13년 전 클라우드 업계에 서버리스라는 바람이 불었고, 8년 전에는 쿠버네티스가 그 자리를 차지했습니다. 그리고 지금 필자는 또 하나의 새로운 흐름 앞에 서 있습니다. AI 에이전트 입니다. 단순히 질문에 답하는 챗봇이 아니라, 사용자 대신 작업을 수행하는 자율 실행체가 엔터프라이즈 워크로드 안으로 들어오기 시작했습니다.
필자 또한 익숙한 패턴대로 도입부터 시작했습니다. Anthropic Claude Desktop을 Azure VM 위에 올리고, MCP 서버를 통해 카카오톡, 주식 API, 파일 시스템과 같은 로컬 도구들을 붙여 본격적으로 운영을 시작했죠. 그리고 모바일에서 명령을 던지면 VM의 에이전트가 그 명령을 받아 실제 작업을 수행하는 Dispatch 모드를 활용하기 시작했습니다.
그런데 운영을 시작하자마자 가장 먼저 떠오른 질문은 기능이 아니라 보안이었습니다.
VM의 인바운드 포트는 닫혀 있는데 어떻게 폰에서 보낸 메시지가 VM 안의 에이전트까지 도달하는가. 이 통신은 어디서 끊어야 하고 어디서 막아야 하는가. 방화벽은 어디에 위치해야 의미가 있는가.
이 질문은 단순한 호기심이 아닙니다. 엔터프라이즈에서 AI 에이전트를 운영한다는 것은 곧 사용자 권한 위임을 의미하며, 이는 곧 새로운 형태의 공격 표면을 의미합니다. 우리가 쿠버네티스 도입 초기에 RBAC, NetworkPolicy, Pod Security Policy를 뒤늦게 학습했던 것과 똑같은 실수를, AI Agent 도입에서 반복해서는 안 됩니다.
Claude Dispatch는 어떻게 동작하는가
먼저 흐름부터 정리합니다. Claude Desktop의 Dispatch는 흔히 오해하기 쉬운 구조를 가집니다. 많은 사람들이 클라우드가 VM에 직접 명령을 내린다고 생각하지만, 실제로는 그렇지 않습니다.
제어 평면(Control Plane) — Anthropic Cloud
Anthropic 클라우드는 메시지를 라우팅할 뿐, 실제로 파일을 읽거나 셸 명령을 실행하지 않습니다. 제어 평면은 메시지의 전달자 역할에 한정됩니다.
실행 평면(Data Plane) — Azure VM
모든 실제 작업은 VM 로컬에서만 일어납니다. 파일 입출력, 셸 실행, MCP 도구 호출(카카오톡, 주식 API 등)이 모두 여기에 해당합니다. 에이전트의 본체는 클라우드가 아니라 VM 안에 있는 Claude Desktop 프로세스입니다.
통신은 항상 Outbound
VM은 부팅 직후 Anthropic 클라우드를 향해 WebSocket 또는 HTTP long-poll로 outbound 연결을 먼저 엽니다. 이 연결은 사용자가 명시적으로 종료하기 전까지 유지됩니다. 폰에서 메시지가 들어오면 클라우드는 이미 열려 있는 그 outbound 채널을 거꾸로 타고 VM에게 메시지를 푸시합니다. 따라서 VM의 NSG에는 인바운드 포트를 단 한 개도 열 필요가 없습니다.
이는 NAT 환경에서 내부 호스트가 먼저 외부에 연결을 맺으면 그 응답 패킷이 방화벽을 거꾸로 통과해 들어오는 것과 같은 원리입니다. Reverse Tunnel, 또는 Long-lived Outbound Channel이라고 부르는 패턴입니다.
다이어그램으로 보는 흐름
전체 흐름을 다이어그램으로 정리하면 아래와 같습니다.
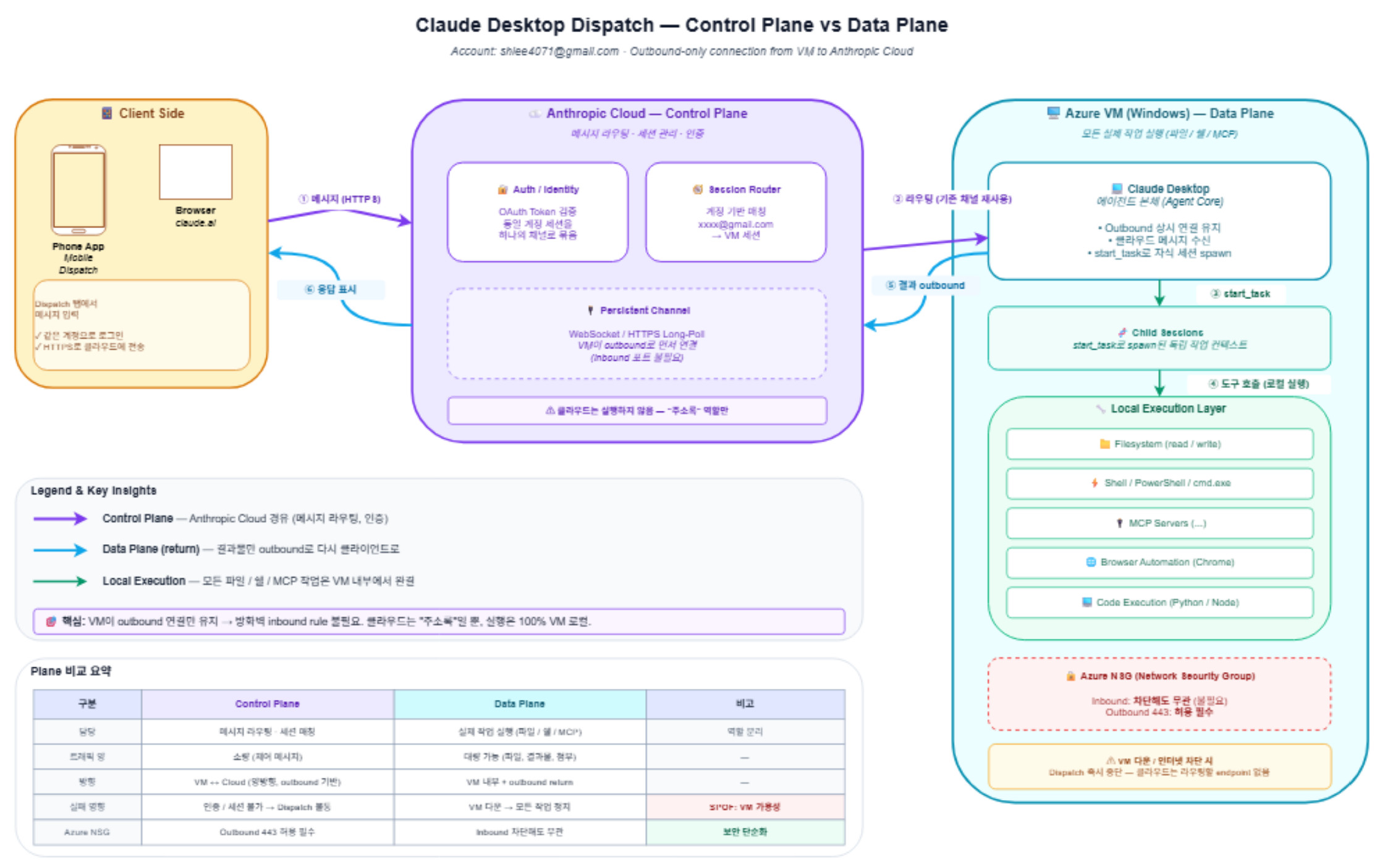
좌측은 클라이언트(폰/브라우저)로 사용자 입력 진입점입니다. 중앙은 Anthropic Cloud로 Control Plane 역할만 수행하며 세션 라우팅에 한정됩니다. 우측은 Azure VM으로 Data Plane이며 에이전트 본체와 모든 실제 실행이 이곳에서 일어납니다. 흐름은 다음과 같습니다. 0번 VM이 outbound 채널을 선개통, 1번 폰에서 메시지 송신, 2번 클라우드 라우팅, 3번 기존 채널로 VM에 푸시, 4번 VM 로컬에서 도구 호출 및 실행, 5번 결과를 outbound로 반환.
여기서 반드시 주목해야 할 보안적 함의는 두 가지입니다.
하나는 공격자 입장에서 VM이 직접 노출되지 않는다는 점입니다. Public IP가 없거나 인바운드가 모두 닫혀 있어도 Dispatch는 동작합니다. 이것은 장점이지만 동시에 함정입니다. 노출되지 않았으니 안전하다는 착각을 줍니다.
다른 하나는 그러나 outbound는 활짝 열려 있다는 점입니다. 그리고 그 outbound 채널을 통해 들어오는 메시지가 곧 임의의 코드 실행 트리거가 됩니다. 누군가 사용자의 Anthropic 계정을 탈취한다면, 그는 VM의 인바운드를 한 줄도 건드리지 않고 VM 안에서 임의의 셸 명령을 실행시킬 수 있습니다.
이 지점에서 우리는 다시 묻게 됩니다. 그럼 보안은 어디서 막아야 하는가.
---
본론 — AI Agent VM의 보안을 어떻게 끌어올릴 것인가
전통적인 클라우드 보안은 인바운드 통제 중심으로 설계되어 있습니다. NSG에서 22, 3389, 443을 닫고, WAF로 L7을 걸러내고, Bastion으로 관리자 접근을 제어합니다. 그러나 Claude Dispatch와 같은 Outbound-First 아키텍처에서는 이 설계가 절반밖에 작동하지 않습니다. 보안 설계의 무게중심을 인바운드에서 아이덴티티와 아웃바운드로 옮겨야 합니다.
필자는 이를 위해 6단계 방어선을 설계했습니다. 1차부터 5차까지는 엔터프라이즈 환경에서 권장하는 표준 방어선이며, 6차는 개인 개발자나 소규모 팀이 Azure Firewall을 도입할 수 없을 때 활용할 수 있는 비용 효율적 대안입니다.
1차 방어선 — Egress Firewall (엔터프라이즈)
Dispatch 채널이 outbound로 열린다는 사실은 곧 outbound 통제가 1차 방화벽이 된다는 뜻입니다. 인바운드를 다 닫아도 outbound가 자유롭다면 보안은 0점입니다.
Azure Firewall 또는 NVA를 Hub VNet에 배치하고, Spoke의 Agent VM은 모든 outbound 트래픽을 강제로 Hub Firewall을 경유하도록 UDR로 강제합니다.
Firewall 정책 (Application Rules) 예시는 다음과 같습니다.
| 우선순위 | 동작 | 대상 FQDN | 목적 |
|---------|------|----------|------|
| 100 | Allow | `*.anthropic.com` | Claude API/Dispatch 연결 |
| 110 | Allow | `*.azure.com`, `*.windowsupdate.com` | OS 패치 |
| 120 | Allow | 지정된 MCP 엔드포인트 | 업무용 MCP 서버 화이트리스트 |
| 9999 | Deny | `*` | 그 외 모든 outbound 차단 |
핵심 원칙은 Default Deny, Whitelist Allow 입니다. Anthropic 도메인 외에는 어디로도 나가지 못하게 하는 것이 가장 중요합니다. 만약 에이전트가 탈취되어 사내 데이터를 외부로 빼내려 한다면 이 Egress Firewall이 마지막 방어선이 됩니다.
다만 Azure Firewall Standard SKU는 시간당 약 1.25 USD, 월 약 900 USD 수준이며, 데이터 처리 비용까지 합치면 월 1,000 USD를 쉽게 넘깁니다. 엔터프라이즈에서는 합리적인 비용이지만 개인 사용자에게는 도입 자체가 불가능한 수준입니다. 이 부분은 6차 방어선에서 별도로 다루겠습니다.
2차 방어선 — Identity & Account Hardening
Dispatch는 본질적으로 Anthropic 계정 기반 라우팅입니다. 계정이 곧 키이며, 계정이 뚫리면 VM이 뚫린 것과 같습니다.
MFA를 반드시 활성화하고, 가능하다면 YubiKey와 같은 Hardware Security Key를 사용합니다. 개인 계정과 Enterprise 운영 계정은 분리합니다. Dispatch 운영용 계정은 절대 일반 채팅용으로 사용하지 않습니다. Anthropic 콘솔의 Active Sessions를 정기적으로 감사하고 비정상 IP나 지역에서의 접속을 차단합니다. Microsoft Entra ID와 SSO 통합이 가능한 환경이라면 지역과 디바이스 기반 Conditional Access 정책으로 접속 자체를 제한합니다.
3차 방어선 — VM Hardening 및 최소 권한
Agent VM은 개발자 데스크탑이 아닌 운영 서버로 다뤄야 합니다.
Azure Defender for Cloud의 JIT VM Access를 켜서 RDP/SSH 인바운드는 평소 닫혀 있고, 관리자가 명시적으로 요청한 시간에만 열리도록 설정합니다. VM에서 다른 Azure 리소스(Storage, Key Vault 등)에 접근할 때는 Access Key를 코드에 박지 말고 System-assigned Managed Identity를 사용합니다. Claude Desktop을 실행하는 사용자는 Local Administrator가 아닌 일반 사용자로 운영합니다. MCP 서버가 시스템 파일을 건드리지 못하게 합니다.
`claude_desktop_config.json`에서 Filesystem MCP의 접근 경로를 명시적으로 좁은 디렉토리로 제한합니다. 예를 들어 `D:AgentWorkspace`만 허용하고, `C:` 루트나 사용자 프로파일 전체는 절대 노출하지 않습니다.
4차 방어선 — MCP Server 자체에 대한 통제
MCP는 강력하지만 그만큼 위험합니다. 외부에서 만든 MCP 서버를 무비판적으로 설치하는 것은 낯선 사람의 USB를 서버에 꽂는 행위와 같습니다.
회사 차원에서 사용 가능한 MCP 서버 목록을 화이트리스트로 관리하고, 사용자가 임의로 추가할 수 없도록 `claude_desktop_config.json` 파일을 GPO 또는 Intune으로 잠급니다. 오픈소스 MCP를 사용할 때는 반드시 소스 코드 리뷰를 거칩니다. 특히 child_process, exec, 외부 네트워크 호출이 있는지 확인합니다. 카카오톡 MCP는 카카오 도메인만, 주식 MCP는 해당 데이터 제공자 도메인만 허용하는 식으로 MCP별로 Egress Firewall 정책을 세분화합니다.
5차 방어선 — Logging, Monitoring & Incident Response
뚫릴 수 있다는 전제 하에 탐지 체계를 갖춰야 합니다.
Azure Monitor Agent와 Log Analytics를 통해 VM 내 프로세스 생성 이벤트(EventID 4688)를 모두 수집합니다. Claude Desktop이 어떤 자식 프로세스를 spawn했는지 전부 기록합니다. Microsoft Defender for Cloud에서 EDR을 활성화하여 비정상적인 PowerShell 실행과 LOLBins를 탐지합니다. Azure Firewall의 모든 Allow/Deny 로그는 Sentinel 또는 Splunk로 전송하여, 안 가야 할 곳으로 가려는 시도를 매일 분석합니다. Anthropic 콘솔에서 제공하는 사용 로그는 정기적으로 다운로드하여 보관합니다(향후 SOC2 감사 대비).
Incident Playbook도 준비합니다. 만약 계정이 탈취되었다고 판단되면 우선 Anthropic 콘솔에서 모든 세션을 강제 종료하고, VM을 즉시 격리하며(NSG로 outbound 전체 차단), 포렌식을 수행한 뒤 새로운 VM으로 재구축합니다. 이 절차를 문서화하고 분기별로 훈련해야 합니다.
6차 방어선 — 개인/소규모 환경의 비용 효율적 대안
지금까지의 방어선은 엔터프라이즈를 가정한 것이며, 1차 Azure Firewall만 해도 월 1,000 USD 수준의 운영비가 발생합니다. 개인 개발자나 소규모 스타트업은 이 비용을 감당하기 어렵습니다. 그렇다고 outbound 통제를 포기할 수는 없습니다. 보안 무게중심이 outbound로 옮겨갔다는 사실은 비용과 무관하게 동일하기 때문입니다.
여기서 솔직하게 짚고 넘어가야 할 기술적 사실이 하나 있습니다. NSG의 ASG(Application Security Group)로 outbound FQDN 필터링이 가능하다는 오해가 흔하지만, 실제로 ASG는 NSG 규칙의 source/destination을 IP 대신 논리적 그룹명으로 표현해주는 라벨일 뿐입니다. NSG 자체가 5-tuple(IP/포트/프로토콜) 기반 L4 필터링만 지원하기 때문에 ASG를 사용하더라도 FQDN 차단은 불가능합니다. Microsoft 공식 문서도 FQDN 필터링은 Azure Firewall에서만 지원된다고 명시하고 있습니다. 이 점을 명확히 하지 않으면 잘못된 보안 설계를 하게 됩니다.
그럼 개인 환경에서 outbound를 어떻게 통제할 것인가. 필자는 다음 4가지 계층을 조합한 무비용 방어 스택을 제안합니다.
계층 1 — NSG + Service Tag (L4 outbound 통제)
NSG는 FQDN을 모르지만 Service Tag는 압니다. Service Tag는 Microsoft가 관리하는 IP 묶음을 이름으로 부르는 기능으로, 무료이고 자동 갱신됩니다.
```
Outbound Rule 100 Allow Destination=AzureCloud Port=443
Outbound Rule 110 Allow Destination=Storage Port=443
Outbound Rule 120 Allow Destination=AzureMonitor Port=443
Outbound Rule 130 Allow Destination=<Anthropic IP> Port=443 (수동 관리)
Outbound Rule 4096 Deny Destination=Internet Port=*
```
Anthropic은 Service Tag가 없으므로 IP 대역을 수동으로 추출해 등록해야 합니다. nslookup이나 dig로 `api.anthropic.com`의 IP를 주기적으로 확인하고, 변동이 있으면 NSG를 갱신하는 PowerShell 스크립트를 Azure Automation으로 스케줄 등록합니다. 갱신 주기는 일 1회면 충분합니다. 이 방식은 완벽하지 않지만 인터넷 전체를 열어두는 것보다 100배 안전합니다.
계층 2 — Windows Defender Firewall (Host-based, 프로세스 단위)
Azure Firewall이 못 하는 것 중 하나가 프로세스 단위 통제입니다. Windows Defender Firewall은 무료이며, 프로세스 단위 outbound 룰을 만들 수 있습니다.
```powershell
# Claude Desktop만 outbound 443 허용, 나머지 모든 프로세스는 차단
New-NetFirewallRule -DisplayName "Allow Claude Desktop Outbound" `
-Direction Outbound -Action Allow `
-Program "C:Users<user>AppDataLocalAnthropicClaudeClaude.exe" `
-Protocol TCP -RemotePort 443
# 기본 outbound 정책을 Block으로 변경 (Default Deny)
Set-NetFirewallProfile -Profile Domain,Public,Private -DefaultOutboundAction Block
```
이 정책을 적용하면 Claude Desktop과 명시적으로 허용한 MCP 프로세스만 인터넷에 나갈 수 있고, 만약 멀웨어가 VM에 침투해 cmd.exe나 powershell.exe로 외부에 데이터를 빼내려 해도 차단됩니다. 다만 Default Deny는 Windows Update나 OS 텔레메트리도 막아버리므로 예외 룰을 충분히 추가해두어야 운영에 지장이 없습니다.
계층 3 — Cloudflare Zero Trust (FQDN 기반 DNS 필터링, 무료 티어)
진짜 FQDN 기반 outbound 통제가 필요하다면 Cloudflare Zero Trust의 무료 티어가 가장 현실적인 선택지입니다. 50명까지 무료이며, WARP 클라이언트를 VM에 설치하면 모든 DNS 쿼리가 Cloudflare를 거치게 됩니다. 여기에 Gateway 정책으로 FQDN 화이트리스트를 적용합니다.
```
Cloudflare Gateway Policy:
- Allow: *.anthropic.com, *.claude.ai
- Allow: *.kakao.com (KakaoTalk MCP)
- Allow: *.windowsupdate.com, *.microsoft.com
- Block: Categories = Malware, Phishing, Newly Registered Domains
- Block: Default (everything else)
```
이 방식은 사실상 Azure Firewall의 Application Rule과 동일한 기능을 무료로 제공합니다. 다만 Cloudflare에 DNS 쿼리 로그가 남는다는 프라이버시 트레이드오프는 인지하고 사용해야 합니다.
계층 4 — Pi-hole 또는 AdGuard Home (자체 호스팅 DNS Sinkhole)
외부 SaaS에 의존하기 싫다면 같은 VNet 내에 작은 Linux VM(B1s, 월 8 USD)을 띄워 Pi-hole을 운영하는 방법도 있습니다. Agent VM의 DNS 서버를 Pi-hole로 지정하고, allowlist에 등록되지 않은 도메인은 모두 sinkhole(0.0.0.0)로 응답하게 설정합니다. 운영 부담은 있지만 모든 통제권을 직접 보유할 수 있습니다.
개인 환경에서 권장하는 최소 조합은 다음과 같습니다.
| 통제 영역 | 도구 | 월 비용 |
|---------|------|--------|
| L4 outbound (IP/포트) | NSG + Service Tag | 0 USD |
| 프로세스 단위 통제 | Windows Defender Firewall | 0 USD |
| FQDN 기반 통제 | Cloudflare Zero Trust Free | 0 USD |
| 합계 | | 0 USD |
이 조합은 Azure Firewall의 기능을 100% 대체하지는 못하지만, outbound 통제의 핵심 원칙인 Default Deny + Whitelist Allow를 무비용으로 구현할 수 있습니다. 엔터프라이즈로 성장한 후에 1차 방어선의 Azure Firewall로 자연스럽게 전환할 수 있도록, 처음부터 화이트리스트 도메인 목록을 문서화해두는 것이 중요합니다.
보안 아키텍처 통합도
6단계 방어선을 통합하면 다음과 같은 그림이 됩니다.
```
[Phone/Browser]
│ (outbound HTTPS, MFA + Conditional Access)
▼
[Anthropic Cloud — Control Plane]
│ (account_id 기반 라우팅)
▼
═══════════════════════════════════════════
엔터프라이즈 — Hub VNet (보안 경계)
┌─────────────────────────────────┐
│ ① Azure Firewall (Egress) │ ← Default Deny
│ - Allow: *.anthropic.com │
│ - Allow: 화이트리스트 MCP │
│ - Deny: 나머지 전부 │
└─────────────────────────────────┘
│ UDR 강제 경유
▼
Spoke VNet (Agent Workload)
┌─────────────────────────────────┐
│ ② Agent VM (JIT, Managed ID) │
│ ├─ Claude Desktop │
│ ├─ MCP (제한된 scope) │
│ └─ Defender for Cloud Agent │
└─────────────────────────────────┘
│
▼
③ Log Analytics + Sentinel (SIEM)
═══════════════════════════════════════════
═══════════════════════════════════════════
개인/소규모 — VNet (6차 방어선)
┌─────────────────────────────────┐
│ NSG + Service Tag │ ← L4 통제 (무료)
├─────────────────────────────────┤
│ Agent VM │
│ ├─ Windows Defender Firewall │ ← 프로세스 단위 (무료)
│ ├─ Cloudflare WARP Client │ ← FQDN 통제 (무료)
│ └─ Claude Desktop + MCP │
└─────────────────────────────────┘
│
▼
Cloudflare Zero Trust Gateway
(FQDN allowlist + Threat Block)
═══════════════════════════════════════════
```
---
결론 — 새로운 패러다임에는 새로운 보안 모델이 필요하다
쿠버네티스가 처음 등장했을 때 우리는 컨테이너가 격리되어 있으니 안전하다고 믿었지만, 곧 RBAC와 NetworkPolicy 없이는 클러스터가 무방비라는 사실을 깨달았습니다. AI Agent가 등장한 지금, 인바운드가 닫혀 있으니 안전하다는 착각에 빠져서는 안 됩니다.
Claude Dispatch는 인바운드를 우회하는 합법적 채널입니다. 보안의 무게중심은 Egress와 Identity, 그리고 MCP Scope로 이동해야 합니다. 인바운드 NSG 한 줄 닫는 것보다 outbound에 Default Deny 정책 한 줄 추가하는 것이 100배 더 효과적입니다.
다만 보안에는 비용이 따릅니다. 엔터프라이즈는 Azure Firewall로 정공법을 쓸 수 있지만 개인은 그럴 수 없습니다. 그렇다고 보안을 포기할 수는 없습니다. NSG + Service Tag, Windows Defender Firewall, Cloudflare Zero Trust 무료 티어를 조합하면 0원으로도 outbound Default Deny를 구현할 수 있습니다. 처음부터 완벽하게 만들 필요는 없습니다. 화이트리스트 도메인 목록을 문서화해두고, 조직이 성장하면 자연스럽게 Azure Firewall로 마이그레이션하면 됩니다.
엔지니어로서 새로운 기술을 빠르게 도입하는 것은 어렵지 않습니다. 그러나 그 기술이 만드는 새로운 위험을 인식하고, 자신의 환경과 예산에 맞는 방어선을 그리는 것, 이것이 진짜 엔터프라이즈 아키텍트의 역할입니다.
]]>| Resource Group | rg-testdemo-openclaw-prod-krc002 | |
| Virtual Machine | vmopenclawkrc002 | |
| Region | Korea Central | |
| VM Size | D8s v3 | |
| User Name | ||
| IP | ||
| RDP port | 3389 | tcp |
Azure Linux를 써야 하는 보안상 이유
AKS 환경에서는 Azure Linux가 Kubernetes 노드 운영을 위해 설계된 최소 Linux 기반 선택지다. Azure는 Kubernetes 노드에서 불필요한 요소를 줄이고 컨테이너 실행 환경에 집중하는 방향으로 Azure Linux를 제공하고 있으며, AKS에서는 node OS image 자동 업그레이드와 같은 기능을 통해 노드를 지속적으로 최신 보안 상태로 유지할 수 있다. 이러한 특성 때문에 Azure Linux는 범용 Linux보다 Kubernetes 노드 역할에 더 집중된 보안 모델을 제공한다. 첫 번째 이유는 Ubuntu 같은 범용 Linux보다 더 작은 운영체제로 설계되어 있다는 점이다. Kubernetes 노드에 필요하지 않은 패키지와 컴포넌트를 줄이고 컨테이너 실행 환경에 집중된 구조를 가지기 때문에 공격 표면이 상대적으로 작다. 패키지 수가 줄어들면 취약점 관리 대상도 함께 줄어들기 때문에 보안 관리 역시 단순해진다. 결국 노드 운영체제가 수행해야 할 역할을 Kubernetes 실행 환경에 집중시키는 구조가 된다. 두 번째 이유는 SSH 접근을 최소화하는 운영 모델과의 궁합이다. AKS 환경에서는 노드에 직접 접속해 문제를 해결하는 방식보다 Kubernetes API와 자동화된 운영 방식이 점점 일반적인 패턴이 되고 있다. Azure Policy에서도 AKS 노드의 SSH 접근을 제한하는 방향을 권장하고 있으며, Azure Linux는 이러한 운영 모델과 자연스럽게 맞는다. 노드에 대한 직접 접근 경로를 줄이면 그 자체로 공격 가능 경로도 줄어들기 때문이다. 세 번째 이유는 node OS image 자동 업그레이드와 결합된 보안 운영 모델이다. AKS는 node OS image 자동 업그레이드를 지원하기 때문에 노드 운영체제를 지속적으로 최신 상태로 유지할 수 있다. 운영자가 수동으로 패치를 관리하는 방식은 종종 누락이나 환경 간 차이를 만들지만, 이미지 기반 업그레이드 방식은 이러한 문제를 줄이고 보안 패치를 더 일관된 방식으로 적용할 수 있게 만든다. 이런 구조는 Kubernetes 환경에서 노드를 수정하기보다 교체하는 운영 모델과도 잘 맞는다. Bottlerocket을 써야 하는 보안상 이유 Bottlerocket은 AWS가 컨테이너 실행 전용으로 만든 OS라서, 일반 서버처럼 이것저것 설치하고 운영하는 전제를 아예 약하게 잡는다. AWS 공식 문서 기준으로 Bottlerocket은 컨테이너 워크로드 실행을 위해 설계된 Linux 기반 오픈소스 OS이고, 보안 강화를 위해 작은 표면적과 이미지 기반 업데이트 방식을 강조한다. 또한 제어용 API를 통해 설정하고, 일반적인 패키지 관리 방식이 아니다. AWS는 EKS용 최적화 노드 OS로 Bottlerocket을 공식 지원한다. 첫째, 불필요한 패키지가 적다. 범용 OS는 편한 대신 디버깅 도구, 패키지 매니저, 각종 유틸리티가 많다. 그만큼 공격면도 넓어진다. Bottlerocket은 컨테이너 호스트 역할에 집중해서 이런 면을 줄인다. 둘째, 노드를 손으로 만지는 운영을 줄인다. 보안 사고는 생각보다 누가 노드에 접속해서 뭘 바꿨는지에서 많이 난다. Bottlerocket은 SSH와 임의 패키지 설치 중심 운영보다, 이미지를 교체하고 노드를 순환시키는 쪽이 자연스럽다. 즉, 운영자의 실수 가능성과 설정 드리프트를 줄이는 데 유리하다. 이는 특히 SOC2, ISO 27001, 내부 보안감사에서 설명하기 좋다. 셋째, 패치 전략이 더 단순하다. 범용 Linux는 서버 안에서 패치라는 사고방식이 남아 있는데, Bottlerocket은 노드 이미지를 갱신하고 교체하는 운영 모델에 더 잘 맞는다. Kubernetes에서는 이 방식이 오히려 더 안전하다. 결론 EKS 환경에서는 여전히 Amazon Linux 기반 노드가 약 50~70% 정도를 차지하고 있고, Bottlerocket이 30~40% 수준으로 사용되는 것으로 알려져 있다. 반면 AKS 환경에서는 Ubuntu 노드가 여전히 70~90% 이상을 차지하며, Azure Linux 기반 노드는 아직 10~20% 이하 수준에 머무르는 경우가 많다. 이러한 차이는 단순히 기술적인 완성도 때문이라기보다는 실제 운영 환경에서의 개발 편의성과 생태계 의존성에서 비롯되는 경우가 많다. Kubernetes 환경에서는 노드를 완전히 표준화하기보다는 개발팀이나 플랫폼팀이 필요에 따라 노드를 커스터마이징하는 경우가 생각보다 많기 때문이다. 하지만 플랫폼 운영 관점에서 보면 노드 커스터마이징은 장기적으로 상당한 운영 리스크를 만든다. 노드에 패키지를 추가하거나 설정을 변경하는 순간부터 환경 간 차이가 발생하고, 시간이 지나면서 클러스터 전체의 일관성이 깨지기 시작한다. 이런 상태에서는 장애가 발생했을 때 트러블슈팅이 복잡해지고, 노드를 교체하는 방식의 운영 모델도 제대로 동작하기 어려워진다. 그래서 Kubernetes 노드는 가능한 한 바닐라 상태를 유지하고, 필요한 경우 Golden Image 기반으로 관리하는 방식이 가장 현실적인 접근이라고 생각한다. 노드를 플랫폼 표준 이미지로 관리하면 환경 간 차이를 줄일 수 있고, 문제 발생 시 노드를 수정하기보다 교체하는 방식의 운영 모델을 유지하기도 훨씬 쉬워진다. 이런 관점에서 보면 Azure Linux가 AKS 환경에서 의미 있는 점유율을 확보하려면 단순히 새로운 Linux 배포판을 제공하는 것만으로는 부족하다. 플랫폼 운영팀이 노드를 별도로 커스터마이징할 필요가 없도록 생태계 의존성과 보안 요구사항을 충분히 커버해야 한다. 즉 Azure Linux 위에서 대부분의 Kubernetes 운영 요구사항이 기본적으로 동작하도록 만들어야 한다. 보안 에이전트, 모니터링 에이전트, 네트워크 플러그인, 스토리지 드라이버 같은 필수 구성 요소들이 별도의 커스터마이징 없이 바로 동작할 수 있어야 실제 운영 환경에서 선택될 가능성이 높아진다. 또 하나 중요한 요소는 장기 지원 체계다. Kubernetes 클러스터는 보통 수년 단위로 운영되는 플랫폼이기 때문에 노드 운영체제 역시 안정적인 LTS 주기를 가져야 한다. 운영팀 입장에서는 OS 지원 주기가 짧으면 클러스터 업그레이드 전략을 세우기 어렵고, 결국 안정적인 플랫폼 운영이 힘들어진다. Azure Linux가 AKS의 기본 노드 운영체제로 자리 잡으려면 이러한 장기 지원 체계가 명확하게 제공되어야 한다. 여기에 더해 Azure 생태계와의 통합도 중요한 요소가 된다. Microsoft Sentinel 같은 SIEM, Defender for Cloud, Azure Policy, Azure Monitor, Log Analytics 같은 Azure 네이티브 보안 및 운영 도구들과 자연스럽게 통합되어야 한다. 이러한 통합이 잘 이루어지면 Azure Linux는 단순한 노드 운영체제가 아니라 Azure 보안 및 운영 플랫폼의 일부로 동작하게 된다. 결국 Azure Linux의 성공 여부는 운영체제 자체의 기술적 특징보다는 플랫폼 관점에서 얼마나 자연스럽게 사용될 수 있는지에 달려 있다고 생각한다. Kubernetes 노드는 가능한 한 바닐라 상태로 유지되고, Golden Image 기반으로 관리되며, 별도의 커스터마이징 없이도 보안과 운영 요구사항을 충족할 수 있어야 한다. 동시에 장기 지원과 Azure 보안 생태계와의 깊은 통합이 제공된다면 Azure Linux는 AKS 환경에서 점유율을 점차 확대해 나갈 수 있을 것이다. ]]>- 사전 정의된 IP 블록 할당: 노드 풀당 정해진 수의 IP 주소를 미리 예약하여 사용
- 효율적인 IP 주소 관리: IP 낭비를 줄이고 서브넷 IP 고갈 문제 완화
- 예측 가능한 네트워크 계획: 고정된 블록으로 네트워크 구조 예측 및 모니터링 용이
- 노드 풀 간 충돌 방지: 각 노드 풀은 고유한 IP 블록을 사용함
- Azure CNI Overlay 모드에서는 적용되지 않음
- 서브넷 크기, 노드 수, 서브넷 IP 용량 등을 정확히 계산해야 IP 충돌 또는 부족 문제 방지 가능
- Pod 수에 따라 필요한 IP 수량을 사전에 계산할 것
Azure Firewall DNAT FQDN 기능 개요
Azure Firewall은 Azure에서 제공하는 클라우드 네이티브 네트워크 보안 서비스로, 인바운드와 아웃바운드 트래픽을 중앙에서 제어할 수 있도록 설계되어 있다. 그중 DNAT(Destination Network Address Translation)는 외부에서 들어오는 트래픽을 내부 네트워크의 특정 리소스로 전달할 때 사용하는 핵심 기능이다. 일반적으로 인터넷에서 접근 가능한 Public IP와 포트를 방화벽에서 받아 내부 VNet에 위치한 서버의 Private IP와 포트로 변환하여 전달하는 방식으로 동작한다. 기존 Azure Firewall의 DNAT 규칙에서는 번역 대상(Translated Address)을 반드시 정적 IP 주소로 지정해야 했다. 이러한 방식은 온프레미스 환경에서는 크게 문제가 되지 않았지만, 클라우드 환경에서는 운영 측면에서 다소 제약이 있었다. 특히 자동 확장 환경이나 Kubernetes 기반 워크로드처럼 백엔드 리소스의 IP가 동적으로 변경되는 구조에서는 DNAT 규칙과 실제 서비스 엔드포인트 간의 동기화를 관리해야 하는 부담이 발생했다. 2025년 6월 Azure Firewall은 DNAT 규칙에서 FQDN(Fully Qualified Domain Name)을 번역 대상으로 지정할 수 있는 기능을 GA(General Availability)로 제공하기 시작했다. 이 기능을 사용하면 방화벽이 DNS를 통해 도메인을 실제 IP 주소로 해석하고, 해당 결과를 기반으로 인바운드 트래픽을 백엔드 리소스로 전달하게 된다. 결과적으로 DNAT 정책을 더 이상 특정 IP에 묶어 둘 필요가 없어지며, DNS 기반으로 관리되는 클라우드 인프라와 보다 유연하게 연동할 수 있게 되었다.DNAT FQDN의 장점
클라우드 환경에서 인프라는 기본적으로 동적인 특성을 가진다. VM Scale Set이나 Kubernetes 같은 플랫폼에서는 인스턴스가 교체되거나 스케일이 조정되는 과정에서 백엔드 IP가 바뀌는 일이 자연스럽게 발생한다. 하지만 기존 DNAT 규칙은 번역 대상이 정적 IP 기반이기 때문에 이러한 환경에서는 운영자가 방화벽 규칙과 실제 서비스 엔드포인트를 계속 맞춰줘야 했다. 서비스 자체는 정상인데 DNAT이 오래된 IP를 가리키고 있어서 연결이 실패하는 상황도 생각보다 자주 발생한다. DNAT에서 FQDN을 사용할 수 있게 되면 이런 종류의 운영 이슈를 상당 부분 줄일 수 있다. 방화벽은 DNS를 통해 대상 리소스를 해석하고 그 결과를 기반으로 트래픽을 전달하기 때문에, 백엔드 인프라의 IP가 변경되더라도 DNAT 규칙 자체를 수정할 필요가 없다. 이 기능은 특히 AKS나 VM Scale Set 같은 환경에서 체감되는 부분이 크다. Kubernetes 환경에서는 서비스 뒤에 있는 Pod나 Node가 교체되는 일이 흔하고, 경우에 따라 서비스 엔드포인트의 IP도 바뀔 수 있다. 기존 방식에서는 이러한 변경이 발생하면 방화벽 DNAT 규칙까지 같이 업데이트해야 할 가능성이 있었지만, FQDN을 사용하면 서비스 DNS만 유지되면 된다. 방화벽 정책이 인프라의 실제 IP에 종속되지 않게 되기 때문에 네트워크 정책과 워크로드의 라이프사이클을 조금 더 분리해서 운영할 수 있다. 배포 전략에서도 활용할 수 있는 부분이 있다. Blue-Green이나 Canary 배포처럼 동일한 서비스를 서로 다른 인프라에 동시에 배치하는 경우에는 트래픽을 점진적으로 새로운 환경으로 이동시키는 과정이 필요하다. DNAT이 특정 IP를 가리키는 구조라면 방화벽 정책을 수정해야 하지만, FQDN 기반이라면 DNS 레코드만 변경해도 백엔드가 자연스럽게 전환된다. 방화벽 정책 자체는 그대로 두고 서비스 엔드포인트만 조정할 수 있기 때문에 배포 과정에서 네트워크 정책을 건드릴 일이 줄어든다. 운영 관점에서도 단순한 장점이 있다. 클라우드 환경에서는 IaC나 자동화 파이프라인으로 인프라를 관리하는 경우가 많지만, 방화벽 규칙이 정적 IP에 묶여 있으면 자동화 흐름이 깨지는 경우가 생긴다. DNAT에서 FQDN을 사용할 수 있게 되면 방화벽 규칙은 서비스 이름을 기준으로 유지할 수 있고, 실제 인프라 변경은 DNS 레이어에서 흡수할 수 있다. 결국 네트워크 정책 관리가 조금 더 단순해지고, 인프라 변경과 보안 정책 사이의 의존성이 줄어드는 구조가 된다.DNAT FQDN의 단점 및 운영 리스크
DNAT에서 FQDN을 사용할 수 있게 되면 운영이 편해지는 부분은 분명 있지만, 동시에 방화벽 정책이 DNS 레이어에 의존하게 된다는 점은 반드시 고려해야 한다. 기존 DNAT은 특정 Private IP를 직접 지정하는 방식이라 동작이 비교적 단순했다. 패킷이 들어오면 지정된 IP로 전달되기 때문에 경로가 명확하다. 반면 FQDN 기반 DNAT은 실제 목적지가 DNS 해석 결과에 따라 결정된다. 결국 네트워크 정책의 일부가 DNS 동작에 영향을 받게 되는 구조가 된다. DNS 인프라가 안정적으로 운영되지 않거나 예상과 다른 응답을 반환하면 DNAT 동작도 그 영향을 그대로 받는다. 개인적으로 운영하면서 가장 신경 쓰이는 부분은 DNS 전파와 캐싱 문제다. 많은 사람들이 DNS 레코드를 변경하면 바로 트래픽이 새로운 대상으로 이동한다고 생각하지만 실제 환경은 그렇게 단순하지 않다. DNS TTL, recursive resolver 캐시, 그리고 Azure Firewall 내부의 FQDN-to-IP 캐시까지 여러 레이어가 동시에 영향을 준다. Azure Firewall은 주기적으로 FQDN을 재해석하지만, DNS 레코드가 변경된 직후에도 일정 시간 동안 이전 IP를 사용하고 있을 수 있다. Blue-Green 배포나 백엔드 전환 과정에서 DNS를 이용해 트래픽을 이동시키는 경우라면 이 타이밍 차이가 실제 장애처럼 보이는 상황을 만들 수 있다. DNS 레코드는 이미 바뀌었는데 일부 트래픽은 여전히 이전 백엔드로 들어가는 상황이 생기는 것이다. 또 하나 현실적으로 마주치는 문제는 하나의 FQDN이 여러 IP로 해석되는 경우다. CDN이나 로드밸런싱 구조에서는 하나의 도메인이 여러 A 레코드를 반환하는 것이 일반적이다. Azure Firewall의 DNS Proxy는 이러한 응답을 받으면 내부적으로 IP 목록을 유지하지만 실제 DNAT 매칭은 그중 첫 번째 IP를 기준으로 동작한다. 이 동작 자체는 문서에도 명시되어 있지만, 서비스가 여러 백엔드로 분산되는 구조라면 기대했던 방식과 다르게 트래픽이 특정 노드로 집중될 가능성도 있다. 특히 DNS 응답 순서가 변경되는 환경에서는 실제 연결 대상이 예상과 다르게 바뀌는 경우도 발생할 수 있다. 보안 측면에서도 DNS 의존성은 고려해야 할 요소다. DNAT 정책이 IP가 아니라 도메인을 기준으로 동작한다는 것은, DNS 응답이 변조되었을 때 트래픽의 목적지 자체가 바뀔 수 있다는 의미이기도 하다. 물론 이는 DNS 인프라 전체의 신뢰성 문제이기도 하지만, 네트워크 보안 장비의 정책이 DNS 결과에 영향을 받는 구조에서는 이 리스크를 조금 더 현실적으로 바라볼 필요가 있다. DNS 보안이 제대로 관리되지 않는 환경이라면 DNAT FQDN은 오히려 예측하기 어려운 트래픽 흐름을 만들 수도 있다. 아키텍처 제약도 있다. 예를 들어 Private DNS 영역과 함께 사용할 경우 일반적인 VNet 기반 환경에서는 문제가 없지만 Virtual WAN 환경에서는 동일하게 동작하지 않는다. Azure Firewall을 Hub-Spoke 형태로 운영하면서 Virtual WAN을 사용하는 아키텍처라면 설계 단계에서 이 부분을 미리 확인해 두는 것이 좋다. 실제 프로젝트에서는 이런 지원 범위 차이가 뒤늦게 발견되는 경우도 생각보다 많다. 마지막으로 운영 가시성 측면에서도 약간의 불편함이 있다. 정적 DNAT은 트래픽이 항상 동일한 IP로 전달되기 때문에 로그 분석이 비교적 단순하다. 하지만 FQDN 기반 DNAT에서는 방화벽이 어떤 시점에 어떤 IP를 DNS로 해석했는지까지 함께 확인해야 한다. AZFWNatRule 로그에는 최종적으로 변환된 IP가 기록되지만, 해당 IP가 어떤 DNS 응답에서 나온 것인지까지 확인하려면 DNS 로그나 DNS Proxy 로그를 함께 봐야 하는 경우가 많다. 결국 트러블슈팅 과정에서 확인해야 할 레이어가 하나 더 생기는 셈이다.Azure Firewall vs AWS Network Firewall 비교 (Cloud Native Firewall 관점)
클라우드 네이티브 방화벽을 이야기할 때 Azure Firewall과 AWS Network Firewall은 자연스럽게 비교 대상이 된다. 두 서비스 모두 퍼블릭 클라우드에서 제공하는 Managed Firewall 서비스지만 실제 사용해 보면 접근 방식이 꽤 다르다는 것을 느끼게 된다. 개인적으로 느끼는 가장 큰 차이는 “하나의 서비스에서 얼마나 많은 네트워크 기능을 해결하려고 하느냐”에 있다.| Feature | Azure Firewall | AWS Network Firewall |
| DNAT FQDN | 지원 (2025 GA) | 제한적 |
| L7 Inspection | 일부 지원 (Premium SKU) | Suricata 기반 DPI |
| DNS 기반 정책 | 지원 | 제한적 |
| Hub-Spoke 아키텍처 | Native 지원 (VNet Hub) | TGW 기반 |
| 관리 모델 | Firewall Policy | Rule Group |
| Feature | Azure Firewall | AWS Firewall | Palo Alto | Fortigate | F5 |
| Cloud Native | Yes | Yes | Partial | Partial | Partial |
| Advanced Threat Protection | Limited | Limited | Strong | Strong | Strong |
| SSL Inspection | Premium | Yes | Yes | Yes | Yes |
| Automation / API | Strong | Strong | Medium | Medium | Medium |
| Operational Complexity | Low | Medium | High | High | High |
| AI Integration Potential | High | High | Medium | Medium | Medium |
| CAPTCHA 비교 | |||
| 구분 | Cloudflare | Google reCAPTCHA | Azure Front Door WAF CAPTCHA |
| 포지셔닝 | 엣지 기반 Bot Management 플랫폼 | 앱 레벨 행위 기반 봇 판별 컴포넌트 | WAF의 보조적 CAPTCHA 기능 |
| 주 사용자 | 보안팀 / 플랫폼팀 | 개발팀 | 보안팀 / 인프라팀 |
| 철학 | “봇을 최대한 보이지 않게 걸러낸다” | “사용자 행위로 봇 확률을 계산한다” | “의심되면 명시적 검증을 시킨다” |
| 아키텍처 위치 | Cloudflare Edge (L7) | 애플리케이션 내부 | Azure Front Door Edge (L7) |
| 코드 수정 | 불필요 | 필수 | 불필요 |
| 트리거 방식 | Bot Score / Rule / Rate / Fingerprint | Score(v3) / Checkbox(v2) | WAF Rule 매칭 |
| 적용 범위 – 웹 | ok | ok | ok |
| 적용 범위 – SPA/AJAX | ok | ok | No |
| 적용 범위 – API | ok | No | No |
| 적용 범위 – 모바일 앱 | ok | ok | No |
| HTML 외 리소스 | ok | ok | No |
| POST Body 제한 | 실질적 제한 없음 | 앱 한계 따름 | 64KB 제한 |
| UX 기본 전략 | 무형(Non-Interactive) 우선 | v3 무형 / v2 인터랙션 | 항상 인터랙션 |
| UX 품질 | 매우 높음 | 매우 높음 | 보통 |
| 사용자 마찰 | 최소 | 최소~보통 | 상대적으로 큼 |
| UX 커스터마이징 | 제한적 | 일부 가능 | 거의 불가 |
| 중앙 통제력 | 매우 강함 | 약함 | 강함 |
| 서비스별 예외 처리 | 용이 | 매우 용이 | 제한적 |
| 보안팀 단독 운영 | 가능 | 불가 | 가능 |
| DevOps 영향 | 낮음 | 높음 | 낮음 |
| 비용 구조 | 패키지/엔터프라이즈 기반 | 무료/유료 티어 | CAPTCHA 세션당 과금 |
| 비용 예측성 | 보통 | 높음 | 낮음 |
| 대규모 공격 시 비용 | 비교적 안정적 | 안정적 | CAPTCHA 트리거 시 증가 |
| 대표적 한계 | 가격·벤더 종속 | 코드 의존·프라이버시 이슈 | 모바일/API 미지원 |
| 적합한 조직 | 대규모 서비스 / 공격 빈번 | 제품 중심 개발 조직 | Azure 중심 엔터프라이즈 |
결론
결론부터 말하면, CAPTCHA를 둘러싼 논의는 기능이 더 좋은가로 흐르기 쉽지만, 실제 운영 환경에서는 누가 통제할 수 있는가가 훨씬 중요하다고 본다. Google reCAPTCHA는 가장 유명하고 완성도도 높다. 하지만 그만큼 애플리케이션 내부에 깊이 들어가 있으며, 인프라 엔지니어나 보안팀이 주도적으로 다루기에는 구조적으로 거리가 있다. 공격이 발생했을 때 개발팀 일정에 맞춰 다음 배포에 반영하는 방식은 현실적으로 너무 느린 경우가 많다. Cloudflare는 이상적인 답에 가깝다. 엣지에서 봇을 조용히 걸러내고, 사용자에게 CAPTCHA를 거의 노출하지 않는다. 보안 아키텍처 관점에서는 가장 깔끔한 접근이다. 다만 이는 Cloudflare를 전사적으로 사용하고 있다는 전제가 붙는다. 비용과 벤더 종속성, 기존 인프라 구조를 고려하지 않고 선택하기는 쉽지 않다. 모든 조직이 Cloudflare를 중심으로 보안 전략을 재구성할 수 있는 상황은 아니다. 이런 맥락에서 보면 Azure Front Door WAF CAPTCHA는 절대적으로 뛰어난 기술이라기보다는 현실적인 도구에 가깝다. 기능은 단순하고 UX도 좋다고 보기는 어렵다. 모바일이나 API 트래픽을 보호할 수 없다는 한계도 명확하다. 그럼에도 불구하고 이 기능이 의미 있는 이유는 Azure 기반 인프라를 운영하는 조직에서 보안팀이나 인프라 엔지니어가 지금 당장 직접 사용할 수 있는 CAPTCHA라는 점이다. 애플리케이션 코드를 수정하지 않고, 개발팀 개입 없이 WAF 정책만으로 로그인 페이지를 보호할 수 있다는 점은 실제 운영에서는 꽤 큰 차이를 만든다. 내 관점에서 이번 Public Preview의 가치는 Azure에도 CAPTCHA가 생겼다는 사실 그 자체가 아니다. 보안 사고 대응의 주도권을 개발팀에서 운영 조직 쪽으로 일부라도 이동시켰다는 점이 핵심이다. 완성도 높은 Bot Management를 기대하면 분명 한계가 느껴질 수 있지만, 크리덴셜 스터핑이나 폼 남용처럼 빈번하게 발생하는 현실적인 공격을 줄이기에는 충분히 의미가 있다. 결국 Azure Front Door WAF CAPTCHA는 최종 해답이라기보다는, 운영 조직이 선택할 수 있는 카드가 하나 더 늘어났다는 점에서 이번 Public Preview는 분명한 의미가 있다고 본다. ]]>| 항목 | AWS SSM (Session Manager) | Azure Bastion |
| 접속 방식 | SSM Session Manager를 통한 터널링 접속 | Azure Portal 기반 RDP / SSH |
| 에이전트 필요 여부 | 필요 (SSM Agent 필수) | 불필요 (Agent-less) |
| 명령어 로그 저장 | 가능 (세션 명령어 기록 가능) | 불가 (접속 로그만 제공, 명령어는 OS 레벨 필요) |
| 로그 저장 위치 | CloudWatch Logs, S3 | Azure Monitor, Log Analytics (접속 메타데이터) |
| IAM 기반 접근 제어 | 가능 (IAM Policy) | 가능 (Azure RBAC + Entra ID) |
| 브라우저 기반 접속 | 가능 | 가능 (Azure Portal) |
| CLI 접속 | AWS CLI | Azure CLI (SSH만 지원) |
| 운영체제 지원 | Linux / Windows | Linux / Windows |
| 기본 보안 수준 | 높음 (에이전트 기반 세션 통제 및 감사 가능) | 높음 (접속 경로 최소화, 인프라 노출 제거) |
| 구성의 복잡함 | 중간 (에이전트 설치, IAM, 로그 설정 필요) | 낮음 (즉시 사용 가능, 구성 최소화) |
| AD 사용 가능 여부 | 직접 불가 (IAM 기반, AD는 Federation 통한 간접 연계만 가능) | 가능 (Azure Entra ID, Hybrid AD 직접 연동) |
| 네트워크 노출 | 공용 IP 불필요 | 공용 IP 불필요 |
| 주요 강점 | 명령어 단위 통제 및 추적 가능 | 단순한 구조, 공격 표면 최소화 |
| 주요 단점 | 에이전트 관리 필요, 운영 복잡성 | 명령어 직접 로깅 불가 |
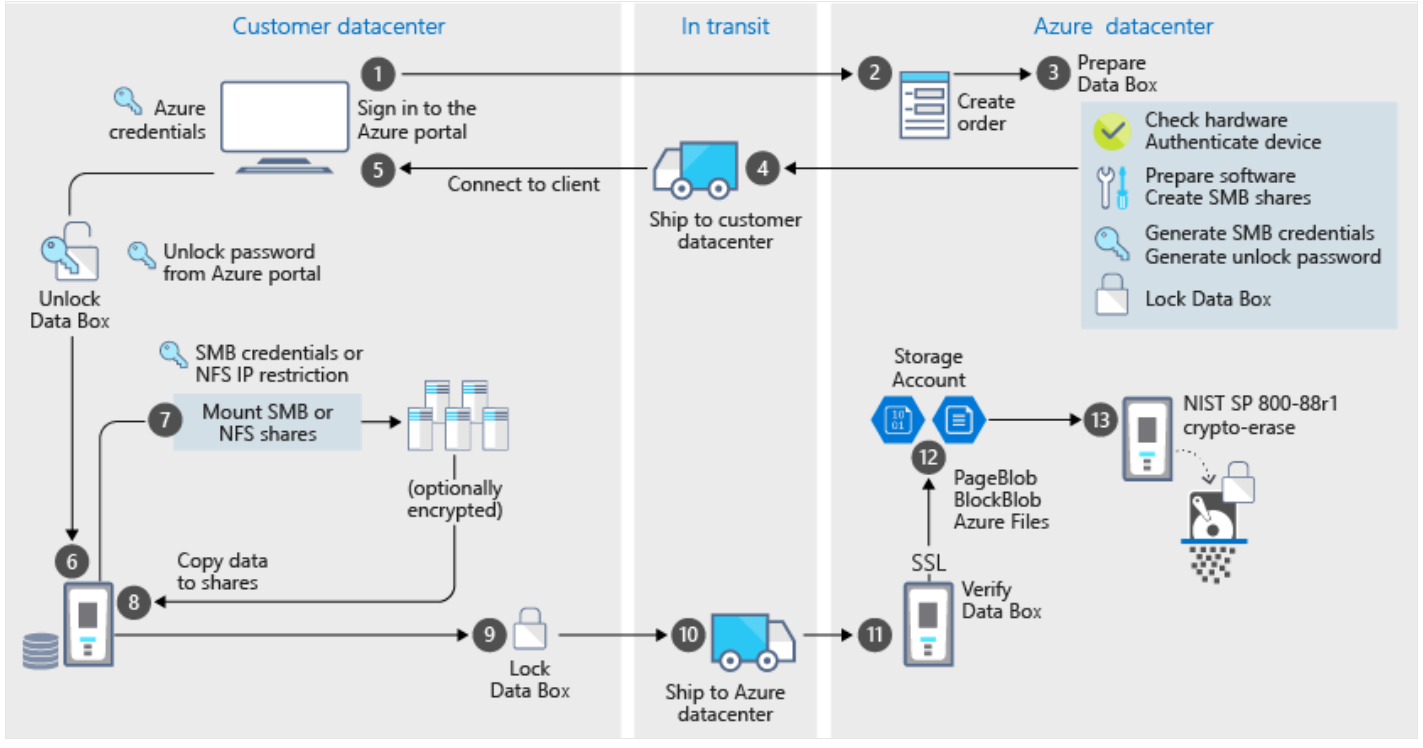 그림001
Azure Data Box 데이터 내보내는 방법 프로세스
1.주문 및 준비 (Azure 데이터 센터)
사용자가 Azure Portal에 로그인하여 Data Box 주문을 생성한다. Azure에서 하드웨어 점검 및 장치 인증을 수행하고, 필요한 소프트웨어 및 SMB 공유를 생성하며, SMB/NFS 자격 증명과 잠금 해제 비밀번호를 만든다. 모든 준비가 완료되면 Data Box를 잠금 상태로 설정하고 고객 데이터 센터로 배송한다.
2.고객 데이터 센터에서 데이터 복사
고객은 Azure Portal을 통해 Data Box에 연결한 후, Azure에서 제공한 암호를 이용해 장치를 잠금 해제한다. 이후 SMB 또는 NFS 공유를 마운트하고, 데이터 암호화 설정을 선택한 뒤, 고객 데이터 센터에서 Data Box로 데이터를 복사한다. 데이터 복사가 완료되면 Data Box를 다시 잠그고 Azure 데이터 센터로 배송한다.
3.Azure 데이터 센터에서 데이터 업로드 및 삭제
Azure 데이터 센터에서 Data Box를 인증 및 검증한 후, SSL을 사용하여 보안을 유지하면서 데이터를 Azure Storage로 업로드한다. 업로드가 완료된 후 NIST SP 800-88r1 표준을 준수하여 crypto-erase 방식으로 데이터를 완전히 삭제하고, 장치를 재사용하거나 폐기한다.
그림001
Azure Data Box 데이터 내보내는 방법 프로세스
1.주문 및 준비 (Azure 데이터 센터)
사용자가 Azure Portal에 로그인하여 Data Box 주문을 생성한다. Azure에서 하드웨어 점검 및 장치 인증을 수행하고, 필요한 소프트웨어 및 SMB 공유를 생성하며, SMB/NFS 자격 증명과 잠금 해제 비밀번호를 만든다. 모든 준비가 완료되면 Data Box를 잠금 상태로 설정하고 고객 데이터 센터로 배송한다.
2.고객 데이터 센터에서 데이터 복사
고객은 Azure Portal을 통해 Data Box에 연결한 후, Azure에서 제공한 암호를 이용해 장치를 잠금 해제한다. 이후 SMB 또는 NFS 공유를 마운트하고, 데이터 암호화 설정을 선택한 뒤, 고객 데이터 센터에서 Data Box로 데이터를 복사한다. 데이터 복사가 완료되면 Data Box를 다시 잠그고 Azure 데이터 센터로 배송한다.
3.Azure 데이터 센터에서 데이터 업로드 및 삭제
Azure 데이터 센터에서 Data Box를 인증 및 검증한 후, SSL을 사용하여 보안을 유지하면서 데이터를 Azure Storage로 업로드한다. 업로드가 완료된 후 NIST SP 800-88r1 표준을 준수하여 crypto-erase 방식으로 데이터를 완전히 삭제하고, 장치를 재사용하거나 폐기한다.
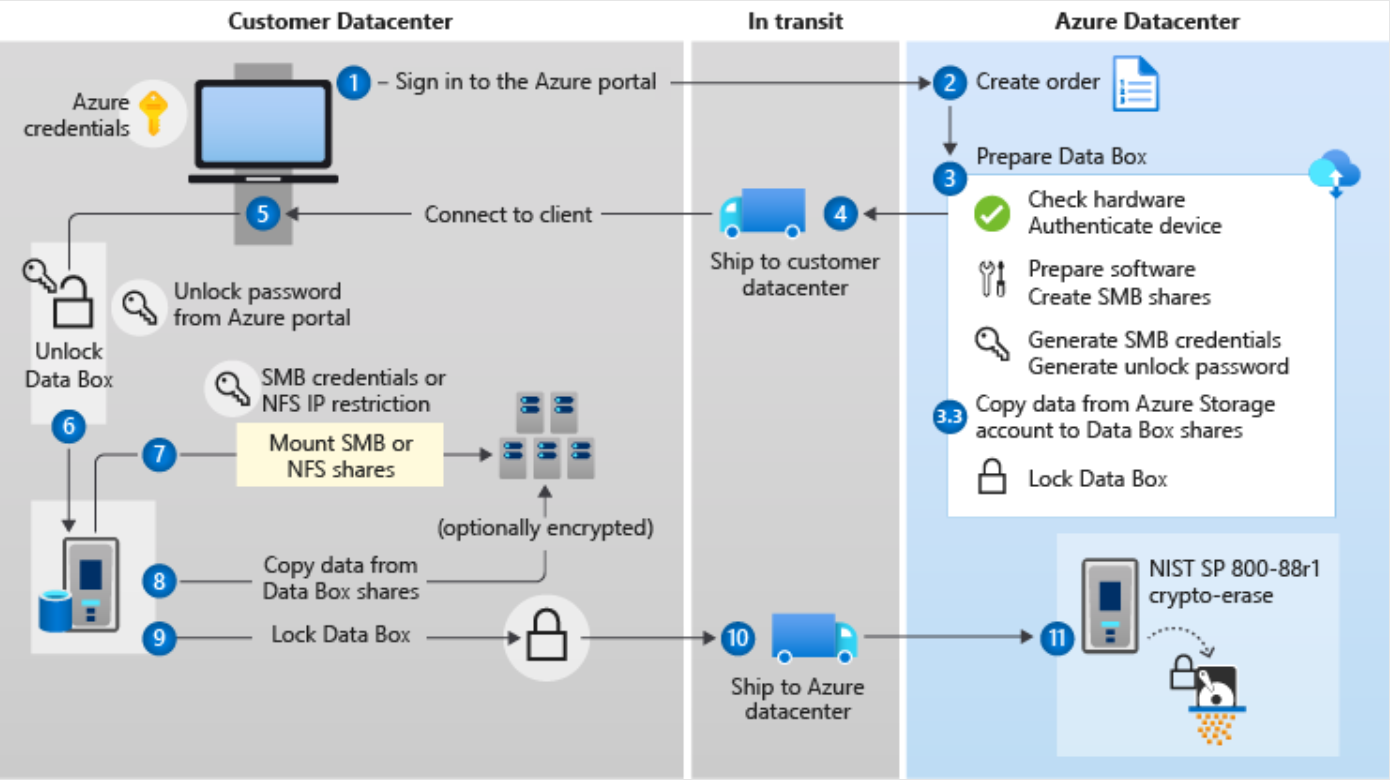 그림002
Azure Data Box 데이터 들어오는 방법 프로세스
1.Azure 포털 로그인 및 주문 생성
사용자가 Azure Portal에 로그인하여 Data Box 주문을 생성한다.
2.Azure 데이터 센터에서 Data Box 준비
하드웨어 점검 및 장치 인증을 수행하고, 필요한 소프트웨어 및 SMB 공유를 생성하며, SMB/NFS 자격 증명과 잠금 해제 비밀번호를 만든다. 또한 Azure Storage 계정에서 Data Box로 데이터를 복사할 수도 있다. 준비가 완료되면 Data Box를 잠금 상태로 설정하고 고객 데이터 센터로 배송한다.
3.고객 데이터 센터에서 데이터 처리
고객은 Azure Portal에서 제공된 암호를 이용해 Data Box를 잠금 해제한 후, SMB 또는 NFS 공유를 마운트하고 데이터를 복사한다. 필요에 따라 Data Box에서 데이터를 읽어와 내부 시스템에 저장할 수도 있다. 데이터 복사가 완료되면 Data Box를 다시 잠근 후 Azure 데이터 센터로 배송한다.
4.Azure 데이터 센터에서 데이터 업로드 및 삭제
Azure에서 Data Box를 인증하고 데이터를 Storage 계정으로 업로드한다. 이후 NIST SP 800-88r1 표준에 따라 crypto-erase 방식을 적용하여 데이터를 완전히 삭제하고 장치를 초기화한다.
결론
최신 세대 Azure Data Box는 데이터 전송 성능과 보안 측면에서 큰 발전을 이뤘습니다. NVMe 디바이스 도입으로 데이터 전송 속도가 개선되었으며, SMB Direct 및 RDMA(100GbE)를 활용한 대용량 파일 처리 성능이 향상되었다. 또한, 데이터 복사 서비스 최적화로 작은 파일부터 대용량 파일까지 전반적인 성능이 증가했습니다. 보안 측면에서도 TPM 2.0, 하드웨어 루트 오브 트러스트(RoT), 암호화된 프로토콜 지원 등으로 물리적·논리적 보안이 강화되었습니다.
그러나 몇 가지 한계점도 존재합니다. 먼저, Azure Data Box의 성능 향상은 최적의 환경에서나 발휘될 가능성이 크며, 실사용에서는 네트워크 인프라나 CPU 성능이 병목이 될 수 있습니다. 또한, 중간 호스트 없이 빠르게 데이터를 전송할 수 있다고 하지만, 파일이 작은 경우 오버헤드가 증가할 가능성이 있으며, 랜덤 액세스가 필요한 경우 성능 저하가 발생할 수 있수 있습니다. 결국, 이 업데이트가 실제 업무 환경에서 얼마나 유의미한 차이를 만들어낼지는 직접적인 테스트와 검증이 필요합니다.
이번 업데이트가 몇 년 만에 이루어졌다는 점에서 Microsoft가 비선호 프로젝트에도 간헐적인 업데이트를 제공하는 것에 감사하지만, AI를 비롯한 특정 분야에 모든 리소스가 집중된 현재의 흐름 속에서 이러한 업데이트는 더욱 소중하게 느껴집니다. 하지만 지속적인 개선을 위해서는 단순한 기능 추가가 아니라 장기적인 로드맵과 인적 리소스 투입이 필수적입니다.
그럼에도 불구하고, 최신 Azure Data Box는 기대할 만한 제품입니다. 대용량 데이터 마이그레이션이 필요한 기업들에게는 여전히 강력한 선택지가 될 것이며, 앞으로 더 자주 업데이트가 이루어진다면 더욱 활용성이 높아질 것으로 보입니다.
참조 링크
https://learn.microsoft.com/en-us/azure/databox/data-box-security?WT.mc_id=AZ-MVP-5002667
]]>
그림002
Azure Data Box 데이터 들어오는 방법 프로세스
1.Azure 포털 로그인 및 주문 생성
사용자가 Azure Portal에 로그인하여 Data Box 주문을 생성한다.
2.Azure 데이터 센터에서 Data Box 준비
하드웨어 점검 및 장치 인증을 수행하고, 필요한 소프트웨어 및 SMB 공유를 생성하며, SMB/NFS 자격 증명과 잠금 해제 비밀번호를 만든다. 또한 Azure Storage 계정에서 Data Box로 데이터를 복사할 수도 있다. 준비가 완료되면 Data Box를 잠금 상태로 설정하고 고객 데이터 센터로 배송한다.
3.고객 데이터 센터에서 데이터 처리
고객은 Azure Portal에서 제공된 암호를 이용해 Data Box를 잠금 해제한 후, SMB 또는 NFS 공유를 마운트하고 데이터를 복사한다. 필요에 따라 Data Box에서 데이터를 읽어와 내부 시스템에 저장할 수도 있다. 데이터 복사가 완료되면 Data Box를 다시 잠근 후 Azure 데이터 센터로 배송한다.
4.Azure 데이터 센터에서 데이터 업로드 및 삭제
Azure에서 Data Box를 인증하고 데이터를 Storage 계정으로 업로드한다. 이후 NIST SP 800-88r1 표준에 따라 crypto-erase 방식을 적용하여 데이터를 완전히 삭제하고 장치를 초기화한다.
결론
최신 세대 Azure Data Box는 데이터 전송 성능과 보안 측면에서 큰 발전을 이뤘습니다. NVMe 디바이스 도입으로 데이터 전송 속도가 개선되었으며, SMB Direct 및 RDMA(100GbE)를 활용한 대용량 파일 처리 성능이 향상되었다. 또한, 데이터 복사 서비스 최적화로 작은 파일부터 대용량 파일까지 전반적인 성능이 증가했습니다. 보안 측면에서도 TPM 2.0, 하드웨어 루트 오브 트러스트(RoT), 암호화된 프로토콜 지원 등으로 물리적·논리적 보안이 강화되었습니다.
그러나 몇 가지 한계점도 존재합니다. 먼저, Azure Data Box의 성능 향상은 최적의 환경에서나 발휘될 가능성이 크며, 실사용에서는 네트워크 인프라나 CPU 성능이 병목이 될 수 있습니다. 또한, 중간 호스트 없이 빠르게 데이터를 전송할 수 있다고 하지만, 파일이 작은 경우 오버헤드가 증가할 가능성이 있으며, 랜덤 액세스가 필요한 경우 성능 저하가 발생할 수 있수 있습니다. 결국, 이 업데이트가 실제 업무 환경에서 얼마나 유의미한 차이를 만들어낼지는 직접적인 테스트와 검증이 필요합니다.
이번 업데이트가 몇 년 만에 이루어졌다는 점에서 Microsoft가 비선호 프로젝트에도 간헐적인 업데이트를 제공하는 것에 감사하지만, AI를 비롯한 특정 분야에 모든 리소스가 집중된 현재의 흐름 속에서 이러한 업데이트는 더욱 소중하게 느껴집니다. 하지만 지속적인 개선을 위해서는 단순한 기능 추가가 아니라 장기적인 로드맵과 인적 리소스 투입이 필수적입니다.
그럼에도 불구하고, 최신 Azure Data Box는 기대할 만한 제품입니다. 대용량 데이터 마이그레이션이 필요한 기업들에게는 여전히 강력한 선택지가 될 것이며, 앞으로 더 자주 업데이트가 이루어진다면 더욱 활용성이 높아질 것으로 보입니다.
참조 링크
https://learn.microsoft.com/en-us/azure/databox/data-box-security?WT.mc_id=AZ-MVP-5002667
]]> 그림001
그림001
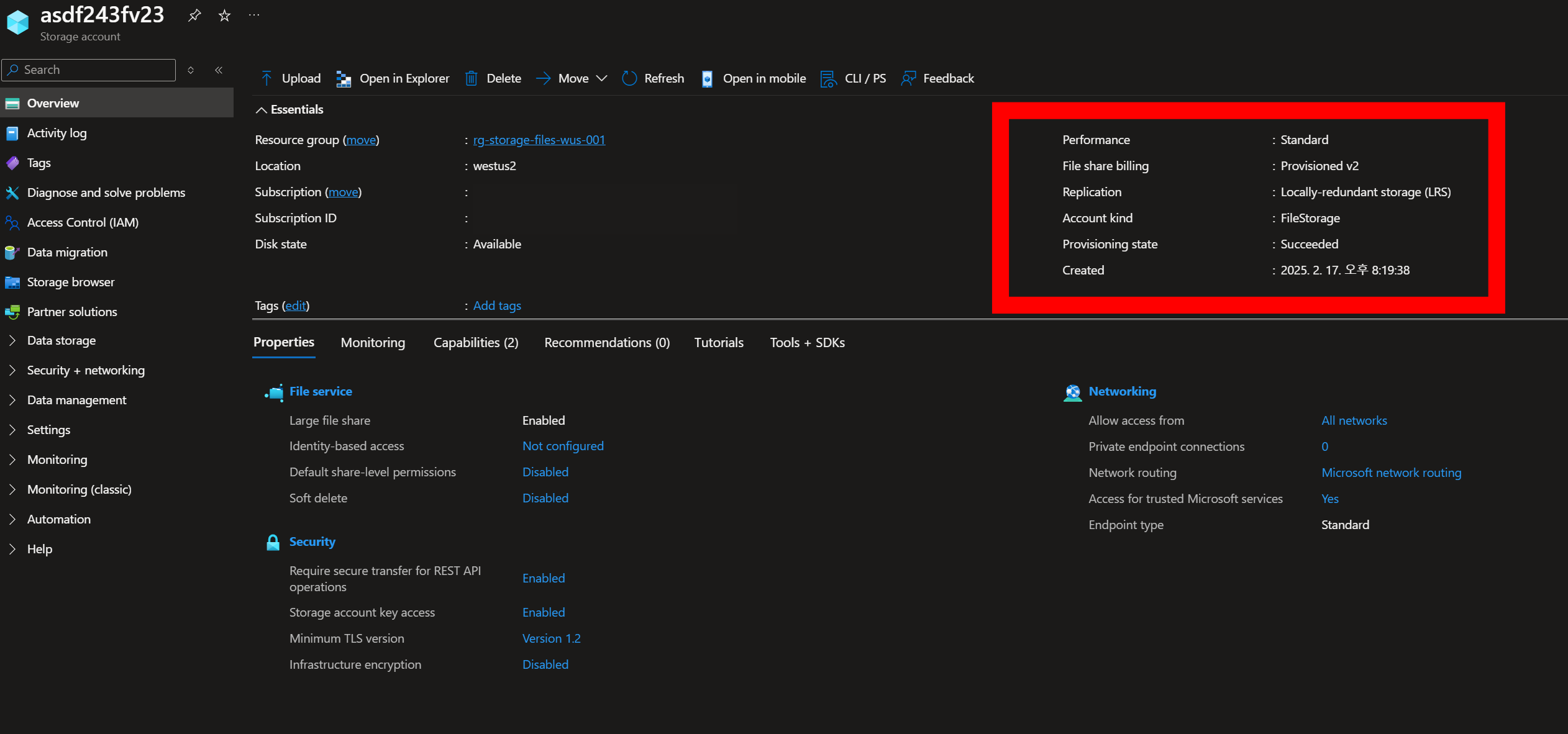 그림002
그림003 처럼 조건을 줄이면 24시간 이내에 한번 만 변경 가능합니다.
그림002
그림003 처럼 조건을 줄이면 24시간 이내에 한번 만 변경 가능합니다.
 그림003
왜 이렇게 V1 v1 standard Premium 으로 나뉘고 구조가 변경될까?
Azure Files의 V1과 V2 계층 구분 및 Premium/Standard 계층의 구조 변경은, 기존 고객들이 사용하고 있던 PaaS(Platform as a Service) 기반 서비스를 호환하면서도 새로운 기능을 추가하려는 진화적 접근 방식에서 비롯된 것입니다.기존 서비스의 호환성 유지는 매우 중요한 부분입니다. 이미 많은 고객들이 기존의 Azure Files V1과 같은 서비스를 사용하고 있기 때문에, 완전히 새로운 구조로 변경하는 것은 고객 경험에 큰 영향을 미칠 수 있습니다. 기존 서비스를 V1으로 제공하고, 점차 V2로 이전하는 방식은 점진적인 변화를 제공하여 기존 고객들이 사용하는 방식에 큰 혼란을 주지 않도록 설계되었습니다.기존의 V1 버전이 점차 낮아지면, V2로 자연스럽게 유도하는 방법이 사용됩니다. 이 방식은 고객 리스크를 줄이기 위한 일반적인 전략입니다. 즉, 기존의 안정적인 V1을 그대로 사용하는 동안 새로운 기능과 성능 향상을 제공하는 V2로의 전환을 유도하는 것입니다. 이러한 전환은 시간이 지나면서 V1이 종료되고, 고객들이 최신 버전으로 점차 이동할 수 있도록 지원합니다.이와 같은 접근은 기존 시스템의 안정성을 유지하면서 새로운 기술적 요구 사항과 기능을 추가하는 데 유리한 방법입니다. 또한, 고객의 서비스 전환을 단계적으로 이루어지게 하여 리스크를 최소화하고, 서비스 제공자와 사용자가 모두 적응할 수 있는 시간을 확보하는 효과를 가져옵니다.
결론
최적의 결과를 얻기 위해서는 스토리지 어카운트에 대한 정교한 디자인이 필요합니다. 설계 단계에서부터 스토리지 구조와 관련된 스큐를 잘 이해하고 이를 반영한다면, 비용 최적화와 최적의 퍼포먼스를 동시에 달성할 수 있습니다. 하지만 이는 쉬운 일이 아닙니다. 스토리지 어카운트는 버전에 맞춰 설계해야 하므로, 상황에 따라 다르게 접근할 수밖에 없기 때문입니다.
하지만 처음부터 스토리지에 대한 깊은 이해가 있다면, Azure Files뿐만 아니라 Blob이나 디스크 등 다양한 스토리지 리소스에 대한 디자인을 효율적으로 구성할 수 있습니다. 지속적인 업데이트가 없다면 설계가 변경될 일이 적겠지만, 클라우드와 AI 시대에 접어들면서, AI를 활용한 자동 스토리지 스큐, IOPS, 처리량과 같은 메트릭을 Azure Copilot이 자동으로 선택하는 시대가 곧 올 것이라고 생각합니다. 이러한 기술 발전이 이루어지면, 스토리지 설계와 최적화는 훨씬 더 자동화되고 효율적으로 진행될 것입니다.]]>
그림003
왜 이렇게 V1 v1 standard Premium 으로 나뉘고 구조가 변경될까?
Azure Files의 V1과 V2 계층 구분 및 Premium/Standard 계층의 구조 변경은, 기존 고객들이 사용하고 있던 PaaS(Platform as a Service) 기반 서비스를 호환하면서도 새로운 기능을 추가하려는 진화적 접근 방식에서 비롯된 것입니다.기존 서비스의 호환성 유지는 매우 중요한 부분입니다. 이미 많은 고객들이 기존의 Azure Files V1과 같은 서비스를 사용하고 있기 때문에, 완전히 새로운 구조로 변경하는 것은 고객 경험에 큰 영향을 미칠 수 있습니다. 기존 서비스를 V1으로 제공하고, 점차 V2로 이전하는 방식은 점진적인 변화를 제공하여 기존 고객들이 사용하는 방식에 큰 혼란을 주지 않도록 설계되었습니다.기존의 V1 버전이 점차 낮아지면, V2로 자연스럽게 유도하는 방법이 사용됩니다. 이 방식은 고객 리스크를 줄이기 위한 일반적인 전략입니다. 즉, 기존의 안정적인 V1을 그대로 사용하는 동안 새로운 기능과 성능 향상을 제공하는 V2로의 전환을 유도하는 것입니다. 이러한 전환은 시간이 지나면서 V1이 종료되고, 고객들이 최신 버전으로 점차 이동할 수 있도록 지원합니다.이와 같은 접근은 기존 시스템의 안정성을 유지하면서 새로운 기술적 요구 사항과 기능을 추가하는 데 유리한 방법입니다. 또한, 고객의 서비스 전환을 단계적으로 이루어지게 하여 리스크를 최소화하고, 서비스 제공자와 사용자가 모두 적응할 수 있는 시간을 확보하는 효과를 가져옵니다.
결론
최적의 결과를 얻기 위해서는 스토리지 어카운트에 대한 정교한 디자인이 필요합니다. 설계 단계에서부터 스토리지 구조와 관련된 스큐를 잘 이해하고 이를 반영한다면, 비용 최적화와 최적의 퍼포먼스를 동시에 달성할 수 있습니다. 하지만 이는 쉬운 일이 아닙니다. 스토리지 어카운트는 버전에 맞춰 설계해야 하므로, 상황에 따라 다르게 접근할 수밖에 없기 때문입니다.
하지만 처음부터 스토리지에 대한 깊은 이해가 있다면, Azure Files뿐만 아니라 Blob이나 디스크 등 다양한 스토리지 리소스에 대한 디자인을 효율적으로 구성할 수 있습니다. 지속적인 업데이트가 없다면 설계가 변경될 일이 적겠지만, 클라우드와 AI 시대에 접어들면서, AI를 활용한 자동 스토리지 스큐, IOPS, 처리량과 같은 메트릭을 Azure Copilot이 자동으로 선택하는 시대가 곧 올 것이라고 생각합니다. 이러한 기술 발전이 이루어지면, 스토리지 설계와 최적화는 훨씬 더 자동화되고 효율적으로 진행될 것입니다.]]> Azure 관리 그룹과 AWS 조직 단위 비교
AWS에서는 계정 간 리소스 공유보다는 완전한 계정 독립성을 유지하면서 중앙에서 관리하는 방식입니다. Azure 관리 그룹 관리 그룹에 속한 구독들은 서로 독립적이지만, 상위 정책을 강제 적용받을 수 있습니다.
클라우드 환경이 점점 복잡해짐에 따라, 대기업 및 조직에서는 단일 계정(AWS)이나 단일 구독(Azure)만으로 리소스를 관리하는 것이 어려워지고 있습니다. 이에 따라 AWS는 조직 단위(Organizational Unit, OU) 개념을, Azure는 관리 그룹(Management Group) 개념을 도입하여 여러 계정(AWS) 또는 구독(Azure)을 보다 효율적으로 관리할 수 있도록 지원하고 있습니다.이 두 개념은 표면적으로 비슷해 보이지만, 클라우드 자원 관리 철학에서 큰 차이점을 가지고 있습니다. Azure는 중앙 집중식 관리 방식을 추구하는 반면, AWS는 각 계정의 독립성을 유지하면서 중앙에서 최소한의 거버넌스를 적용하는 방식을 선호합니다.
Azure 관리 그룹과 AWS 조직 단위 비교
AWS에서는 계정 간 리소스 공유보다는 완전한 계정 독립성을 유지하면서 중앙에서 관리하는 방식입니다. Azure 관리 그룹 관리 그룹에 속한 구독들은 서로 독립적이지만, 상위 정책을 강제 적용받을 수 있습니다.
클라우드 환경이 점점 복잡해짐에 따라, 대기업 및 조직에서는 단일 계정(AWS)이나 단일 구독(Azure)만으로 리소스를 관리하는 것이 어려워지고 있습니다. 이에 따라 AWS는 조직 단위(Organizational Unit, OU) 개념을, Azure는 관리 그룹(Management Group) 개념을 도입하여 여러 계정(AWS) 또는 구독(Azure)을 보다 효율적으로 관리할 수 있도록 지원하고 있습니다.이 두 개념은 표면적으로 비슷해 보이지만, 클라우드 자원 관리 철학에서 큰 차이점을 가지고 있습니다. Azure는 중앙 집중식 관리 방식을 추구하는 반면, AWS는 각 계정의 독립성을 유지하면서 중앙에서 최소한의 거버넌스를 적용하는 방식을 선호합니다.
 AWS 계정과 Azure 구독의 비교
AWS 계정과 Azure 구독은 클라우드 리소스를 관리하는 기본 단위로 유사한 개념을 가지지만, 운영 방식에서 차이가 있습니다. AWS 계정은 기본적으로 완전히 독립적인 환경을 제공하며, IAM(Role 및 Policy)으로 개별적으로 권한을 관리하고, 계정 간 네트워크 연결 시 별도의 VPC Peering이나 AWS Transit Gateway 설정이 필요합니다. 또한, 청구 역시 계정 단위로 독립적으로 이루어지며, 비용을 통합 관리하려면 AWS Organizations의 Consolidated Billing 기능을 활용해야 합니다. 반면, Azure 구독은 Microsoft Entra 테넌트 내에서 중앙 집중적으로 관리되며, 테넌트 내 여러 구독 간 협업과 리소스 공유가 용이합니다. 권한 관리도 RBAC(Role-Based Access Control)를 통해 일관된 정책을 적용할 수 있으며, 네트워크 연결도 VNet Peering을 통해 상대적으로 간편하게 설정할 수 있습니다. 또한, 청구는 동일한 청구 계정(Billing Account) 아래 여러 구독을 통합하여 관리할 수 있어, 비용 할당이 비교적 수월합니다. 리소스 할당량 측면에서도 AWS는 계정별 조정이 유연한 반면, Azure는 일부 제한이 고정적이라 변경이 불가능한 경우가 있어 이를 고려해야 합니다. 결과적으로, AWS는 계정 단위의 독립성과 보안 경계를 강조하는 반면, Azure는 테넌트 중심의 중앙 집중적 관리를 기반으로 운영된다는 점이 주요 차이점입니다.
보안
AWS의 서비스 제어 정책(SCP)과 Azure 정책은 모두 클라우드 리소스에 대한 권한 및 규정 준수를 관리하는 중요한 도구입니다. AWS SCP는 주로 각 AWS 계정 내에서 최대 유효 권한을 제한하는 데 사용되며, 계정 단위로 독립적인 보안 경계를 설정합니다. 그러나 이 모델은 계정 간 리소스 공유 시 보안 구멍이 발생할 수 있는 위험이 존재합니다. 반면, Azure 정책은 Microsoft Entra 기반으로 중앙 집중적인 접근 방식을 채택, 테넌트 수준에서 정책을 정의하고 구독, 리소스 그룹 및 리소스 수준에서 적용할 수 있습니다. 이로 인해 Azure는 보안이 보다 일관되게 적용되며, 엔터프라이즈 표준을 준수할 수 있도록 사전 예방적으로 관리할 수 있습니다. 또한 Azure 정책은 기존 리소스와 향후 배포를 모두 평가하고 규정 준수 상태를 유지하기 위한 수정 작업을 자동으로 트리거할 수 있어 보안 구멍이 발생할 가능성이 낮습니다. 결국, AWS는 계정 기반으로 보안 관리가 독립적이기 때문에 보안 구멍이 발생할 수 있는 여지가 있지만, Azure는 중앙 집중적인 보안 관리와 정책 적용을 통해 보다 일관된 보안을 제공합니다.
결론
AWS와 Azure는 각각 고유한 방식으로 클라우드 리소스를 관리하고 보안을 구현합니다. AWS는 계정 기반의 독립적인 관리 방식을 채택하여 각 계정에 대해 세밀한 제어가 가능하지만, 계정 간 리소스 공유와 보안 측면에서 취약점이 발생할 수 있습니다. 반면, Azure는 중앙 집중적인 관리 모델을 통해 하나의 테넌트 내에서 구독과 리소스를 효율적으로 관리하고, 정책을 통해 보안을 일관되게 유지할 수 있습니다. 특히, Azure의 Microsoft Entra와 Azure 정책은 보안을 사전 예방적으로 관리하고, 리소스 간의 연동 및 규정 준수를 효율적으로 처리하는 데 강점을 보입니다. 따라서, 기업의 클라우드 인프라 관리에서 AWS는 보다 분산적인 접근을 제공하는 반면, Azure는 중앙 집중적이고 통합적인 관리 방식을 통해 보안을 강화할 수 있는 장점이 있습니다. Azure 경우 Microsoft Entra를 기반으로 하는 Azure의 AD 관리 기능은 오랜 역사를 자랑하며 강력한 보안 기능을 제공합니다. 개인적으로는 Azure AD가 AWS의 AD 관리 기능을 넘어서는 데 어려움이 있을 것으로 보지만, AWS 또한 기본적인 기능을 충분히 제공하며, 특정 사용 사례에서는 그 기능을 활용할 수 있습니다.각 플랫폼의 장단점을 충분히 알고 있는 것이 중요합니다.
]]>
AWS 계정과 Azure 구독의 비교
AWS 계정과 Azure 구독은 클라우드 리소스를 관리하는 기본 단위로 유사한 개념을 가지지만, 운영 방식에서 차이가 있습니다. AWS 계정은 기본적으로 완전히 독립적인 환경을 제공하며, IAM(Role 및 Policy)으로 개별적으로 권한을 관리하고, 계정 간 네트워크 연결 시 별도의 VPC Peering이나 AWS Transit Gateway 설정이 필요합니다. 또한, 청구 역시 계정 단위로 독립적으로 이루어지며, 비용을 통합 관리하려면 AWS Organizations의 Consolidated Billing 기능을 활용해야 합니다. 반면, Azure 구독은 Microsoft Entra 테넌트 내에서 중앙 집중적으로 관리되며, 테넌트 내 여러 구독 간 협업과 리소스 공유가 용이합니다. 권한 관리도 RBAC(Role-Based Access Control)를 통해 일관된 정책을 적용할 수 있으며, 네트워크 연결도 VNet Peering을 통해 상대적으로 간편하게 설정할 수 있습니다. 또한, 청구는 동일한 청구 계정(Billing Account) 아래 여러 구독을 통합하여 관리할 수 있어, 비용 할당이 비교적 수월합니다. 리소스 할당량 측면에서도 AWS는 계정별 조정이 유연한 반면, Azure는 일부 제한이 고정적이라 변경이 불가능한 경우가 있어 이를 고려해야 합니다. 결과적으로, AWS는 계정 단위의 독립성과 보안 경계를 강조하는 반면, Azure는 테넌트 중심의 중앙 집중적 관리를 기반으로 운영된다는 점이 주요 차이점입니다.
보안
AWS의 서비스 제어 정책(SCP)과 Azure 정책은 모두 클라우드 리소스에 대한 권한 및 규정 준수를 관리하는 중요한 도구입니다. AWS SCP는 주로 각 AWS 계정 내에서 최대 유효 권한을 제한하는 데 사용되며, 계정 단위로 독립적인 보안 경계를 설정합니다. 그러나 이 모델은 계정 간 리소스 공유 시 보안 구멍이 발생할 수 있는 위험이 존재합니다. 반면, Azure 정책은 Microsoft Entra 기반으로 중앙 집중적인 접근 방식을 채택, 테넌트 수준에서 정책을 정의하고 구독, 리소스 그룹 및 리소스 수준에서 적용할 수 있습니다. 이로 인해 Azure는 보안이 보다 일관되게 적용되며, 엔터프라이즈 표준을 준수할 수 있도록 사전 예방적으로 관리할 수 있습니다. 또한 Azure 정책은 기존 리소스와 향후 배포를 모두 평가하고 규정 준수 상태를 유지하기 위한 수정 작업을 자동으로 트리거할 수 있어 보안 구멍이 발생할 가능성이 낮습니다. 결국, AWS는 계정 기반으로 보안 관리가 독립적이기 때문에 보안 구멍이 발생할 수 있는 여지가 있지만, Azure는 중앙 집중적인 보안 관리와 정책 적용을 통해 보다 일관된 보안을 제공합니다.
결론
AWS와 Azure는 각각 고유한 방식으로 클라우드 리소스를 관리하고 보안을 구현합니다. AWS는 계정 기반의 독립적인 관리 방식을 채택하여 각 계정에 대해 세밀한 제어가 가능하지만, 계정 간 리소스 공유와 보안 측면에서 취약점이 발생할 수 있습니다. 반면, Azure는 중앙 집중적인 관리 모델을 통해 하나의 테넌트 내에서 구독과 리소스를 효율적으로 관리하고, 정책을 통해 보안을 일관되게 유지할 수 있습니다. 특히, Azure의 Microsoft Entra와 Azure 정책은 보안을 사전 예방적으로 관리하고, 리소스 간의 연동 및 규정 준수를 효율적으로 처리하는 데 강점을 보입니다. 따라서, 기업의 클라우드 인프라 관리에서 AWS는 보다 분산적인 접근을 제공하는 반면, Azure는 중앙 집중적이고 통합적인 관리 방식을 통해 보안을 강화할 수 있는 장점이 있습니다. Azure 경우 Microsoft Entra를 기반으로 하는 Azure의 AD 관리 기능은 오랜 역사를 자랑하며 강력한 보안 기능을 제공합니다. 개인적으로는 Azure AD가 AWS의 AD 관리 기능을 넘어서는 데 어려움이 있을 것으로 보지만, AWS 또한 기본적인 기능을 충분히 제공하며, 특정 사용 사례에서는 그 기능을 활용할 수 있습니다.각 플랫폼의 장단점을 충분히 알고 있는 것이 중요합니다.
]]>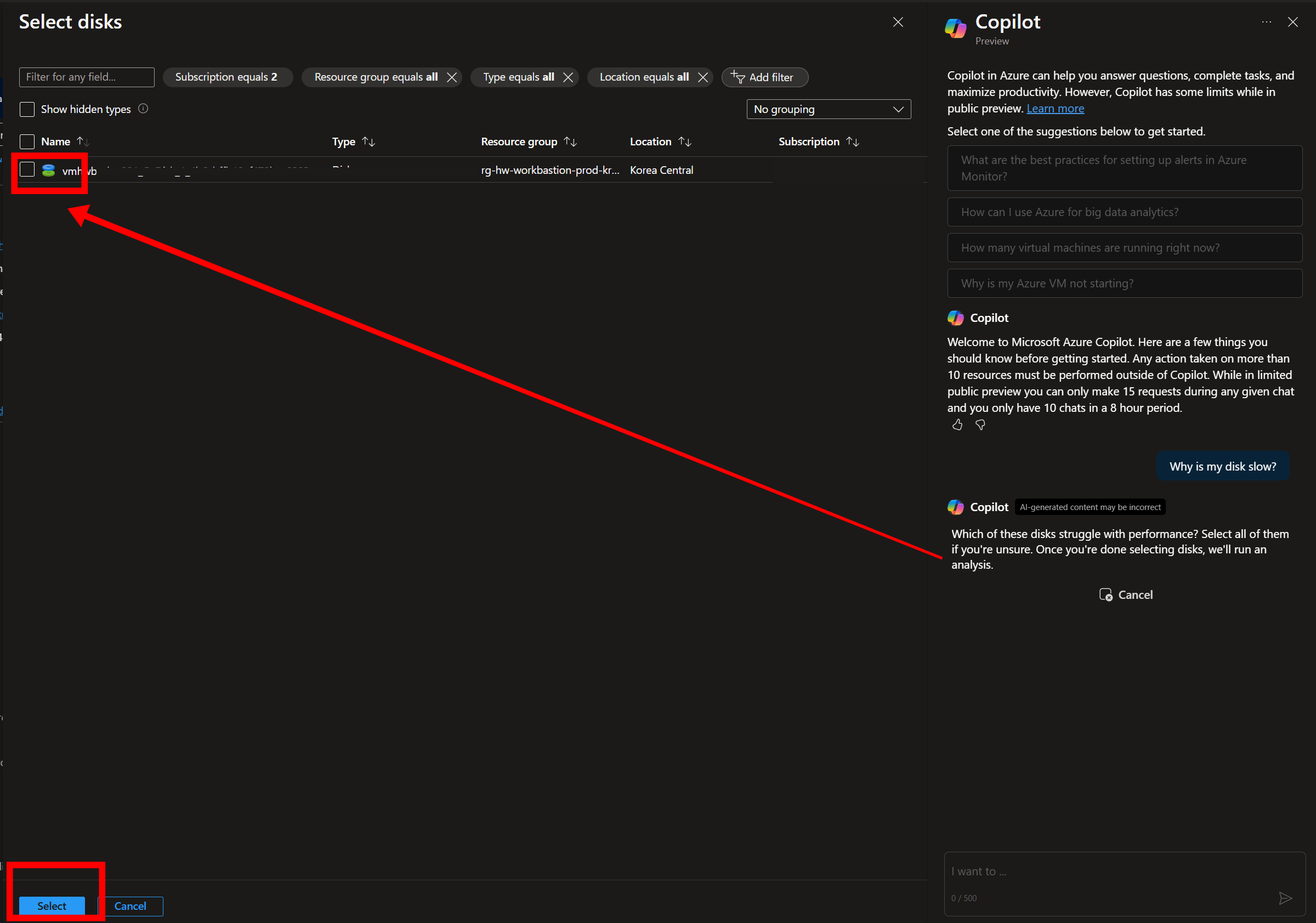 그림001
3.언제 퍼포먼스가 이슈가 있었는지 Copilot이 대화형으로 질문합니다.
4.I have an exact time 답변을 선택합니다.
그림001
3.언제 퍼포먼스가 이슈가 있었는지 Copilot이 대화형으로 질문합니다.
4.I have an exact time 답변을 선택합니다.
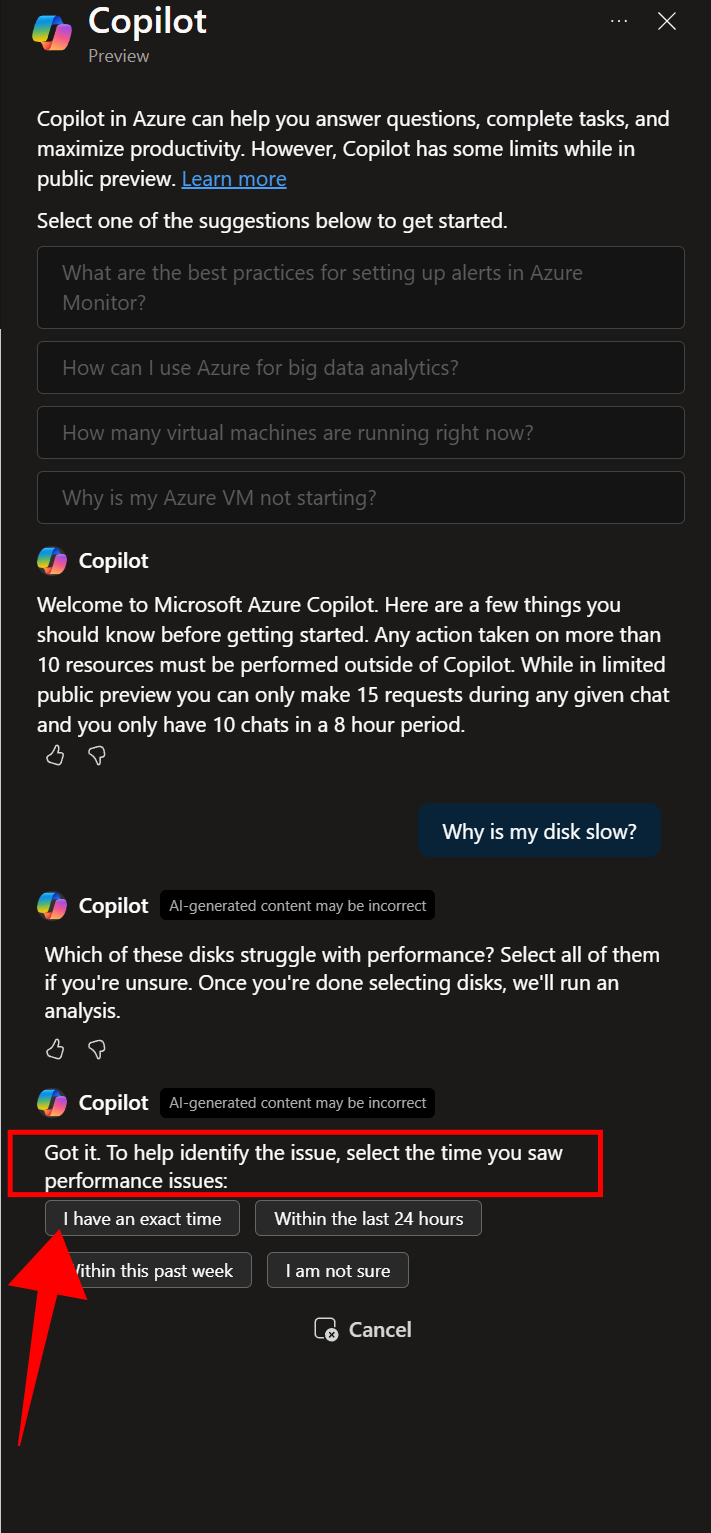 그림002
5. 정확한 시간을 입력합니다.
그림002
5. 정확한 시간을 입력합니다.
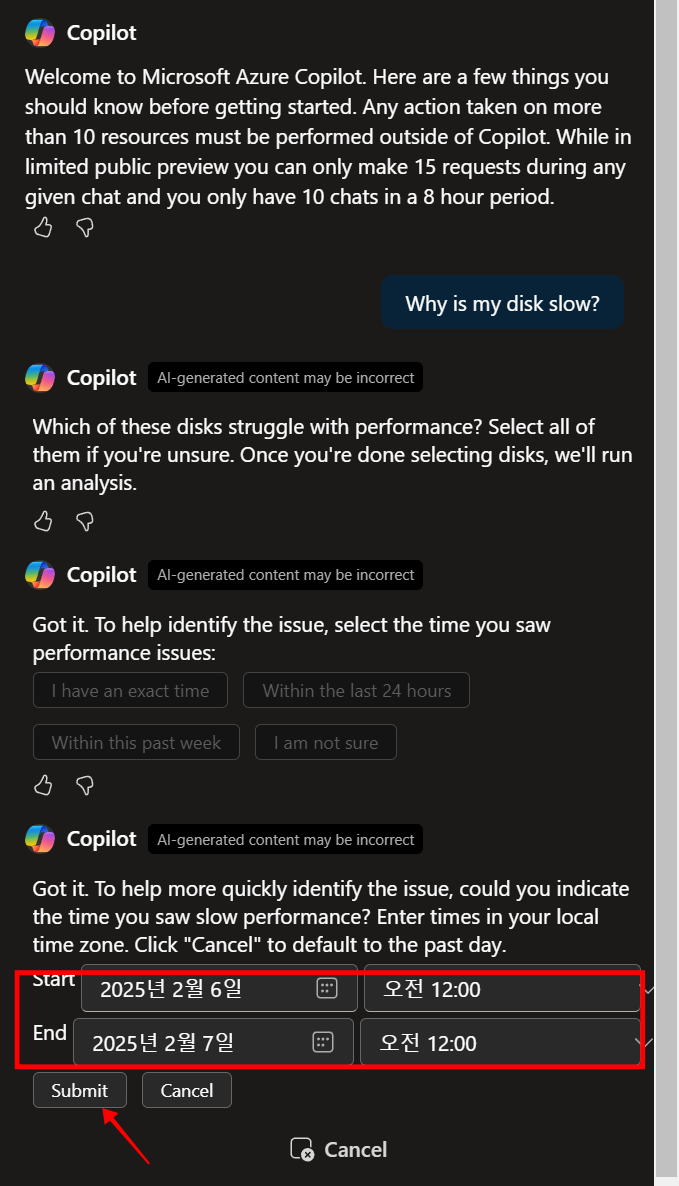 그림003
6. 선택한 디스크의 Azure 모니터링 지표에서 메트릭을 통해서 분석 합니다.
그림003
6. 선택한 디스크의 Azure 모니터링 지표에서 메트릭을 통해서 분석 합니다.
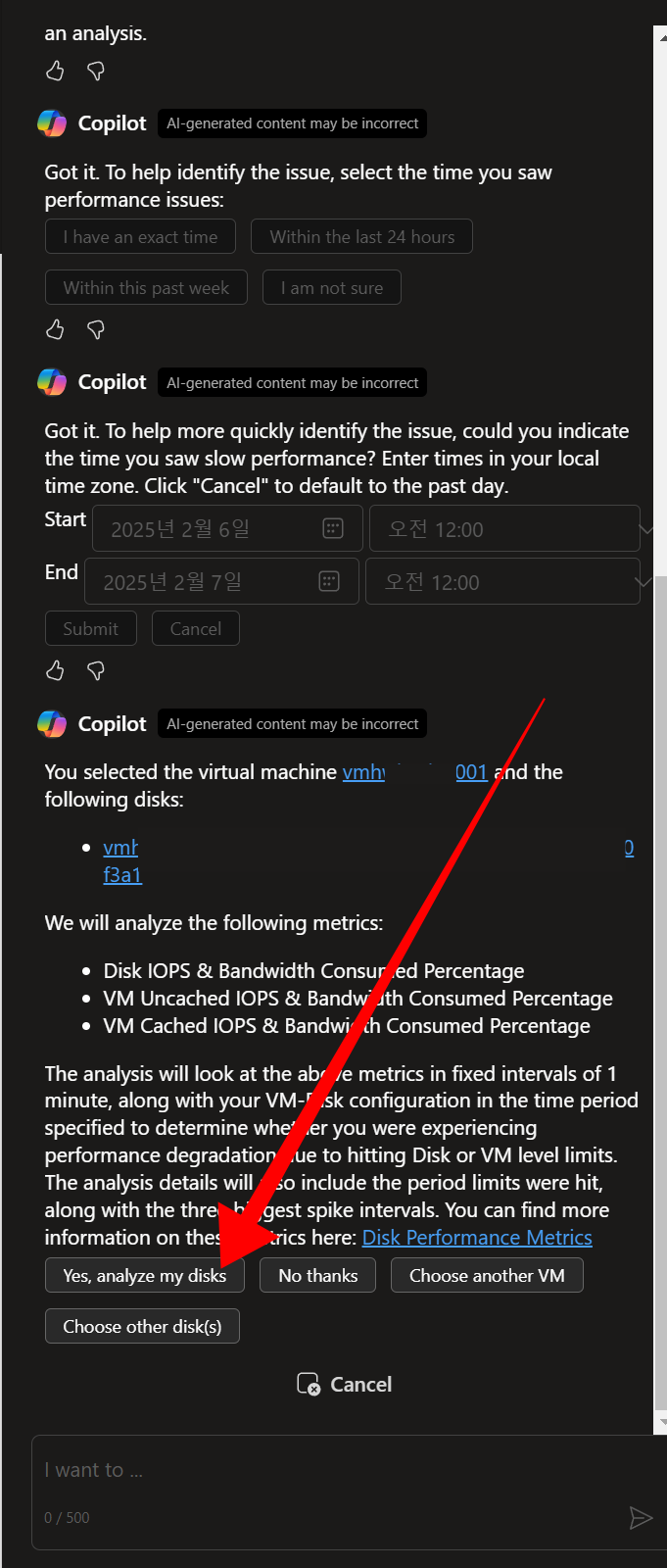 그림004
7. 분석 결과가 나옵니다.
그림005
분석:
디스크와 연결된 가상 머신이 새로 생성되었거나 지정된 기간 동안 비활성 상태였던 것으로 보입니다. 이러한 비활성 상태로 인해 디스크 성능 문제를 효과적으로 분석하기에 충분한 데이터가 제공되지 않을 수 있습니다.
권장 작업:
분석 재시도: 가능하면 가상 머신이 활성화되었던 다른 기간으로 다시 시도하여 더 관련성 있는 성능 데이터를 수집하세요.
활동 모니터링: 가상 머신이 실행 중이고 워크로드를 적극적으로 처리하여 성능 메트릭을 캡처하는지 확인하세요.
추가 정보:
계속해서 속도가 느려지면 가상 머신 구성과 디스크 설정을 확인하여 워크로드에 최적화되었는지 확인하세요.
디스크 성능 최적화에 대한 자세한 내용은 Azure 설명서를 참조하세요.
분석에 대한 피드백
테스트를 통해서 새로 생성한 디스크인것을 완전히 정확히 분석 했으며 권장 작업이 대화형으로 다른 분석을 할수 있도록 도움을 줍니다. 기존 서포트에 대한 설명링크의 경우는 매우 일반적인 설명 링크나 서포트 + 트러블 슈팅을 포털에서 제공하던 것과 비교했을때 드라마틱하게 대화형이며 내정보 기반으로 분석 해주기 때문에 많은 도움이 됩니다.
그림004
7. 분석 결과가 나옵니다.
그림005
분석:
디스크와 연결된 가상 머신이 새로 생성되었거나 지정된 기간 동안 비활성 상태였던 것으로 보입니다. 이러한 비활성 상태로 인해 디스크 성능 문제를 효과적으로 분석하기에 충분한 데이터가 제공되지 않을 수 있습니다.
권장 작업:
분석 재시도: 가능하면 가상 머신이 활성화되었던 다른 기간으로 다시 시도하여 더 관련성 있는 성능 데이터를 수집하세요.
활동 모니터링: 가상 머신이 실행 중이고 워크로드를 적극적으로 처리하여 성능 메트릭을 캡처하는지 확인하세요.
추가 정보:
계속해서 속도가 느려지면 가상 머신 구성과 디스크 설정을 확인하여 워크로드에 최적화되었는지 확인하세요.
디스크 성능 최적화에 대한 자세한 내용은 Azure 설명서를 참조하세요.
분석에 대한 피드백
테스트를 통해서 새로 생성한 디스크인것을 완전히 정확히 분석 했으며 권장 작업이 대화형으로 다른 분석을 할수 있도록 도움을 줍니다. 기존 서포트에 대한 설명링크의 경우는 매우 일반적인 설명 링크나 서포트 + 트러블 슈팅을 포털에서 제공하던 것과 비교했을때 드라마틱하게 대화형이며 내정보 기반으로 분석 해주기 때문에 많은 도움이 됩니다.
Copilot이 나아가야 할 방향
Microsoft Copilot의 디스크 성능 문제 해결 기능은 AI를 활용한 클라우드 운영 최적화의 한 걸음으로 볼 수 있습니다. 그러나 이 기능이 단순한 진단 도구에서 벗어나 실제 운영 환경에서 신뢰할 수 있는 성능 최적화 솔루션으로 자리 잡기 위해서는 몇 가지 중요한 방향성이 필요합니다. 첫째, 보다 정밀한 분석 및 복합적인 문제 해결 능력 강화 현재 Copilot은 VM-Disk 구성 내에서 성능 문제를 감지하고 기본적인 최적화 방안을 제시하는 수준에 머물러 있습니다. 그러나 클라우드 인프라의 성능 문제는 네트워크 병목, 애플리케이션 아키텍처, 스토리지 계층 구조 등 다양한 요소가 얽혀 있습니다. 따라서 Copilot이 단순히 디스크 성능 최적화를 제안하는 것이 아니라, 이러한 다양한 요소를 종합적으로 분석하고 상관관계를 찾아주는 AI 모델로 발전해야 합니다. 둘째, 자동화 기능의 신뢰성 강화 및 사용자 제어 옵션 확대 자동화된 성능 최적화가 모든 환경에 적합할 수는 없습니다. 현재 Copilot이 제안하는 해결책이 Azure Portal을 통해 바로 적용될 수 있지만, IT 운영자는 이러한 변경이 실제 시스템에 미칠 영향을 충분히 검토해야 합니다. 따라서 Copilot은 최적화 적용 전에 예상되는 성능 변화와 위험 요소를 명확하게 설명하는 기능을 추가해야 하며, 운영자가 이를 세부적으로 조정할 수 있도록 유연한 제어 옵션을 제공해야 합니다.결론
Copilot의 디스크 성능 문제 해결 기능은 AI 기반 인프라 최적화의 가능성을 보여주지만, 보다 정밀한 문제 해결 능력, 신뢰할 수 있는 자동화 적용, 단순한 AI 도우미가 아니라 실제 IT 운영자가 신뢰하고 활용할 수 있는 AI 기반 운영 최적화 솔루션으로 발전하기 위해서는, 이러한 방향으로 지속적인 개선이 이루어져야 할 것입니다.]]> 그림2 스팟 점수 평가
그림2 스팟 점수 평가
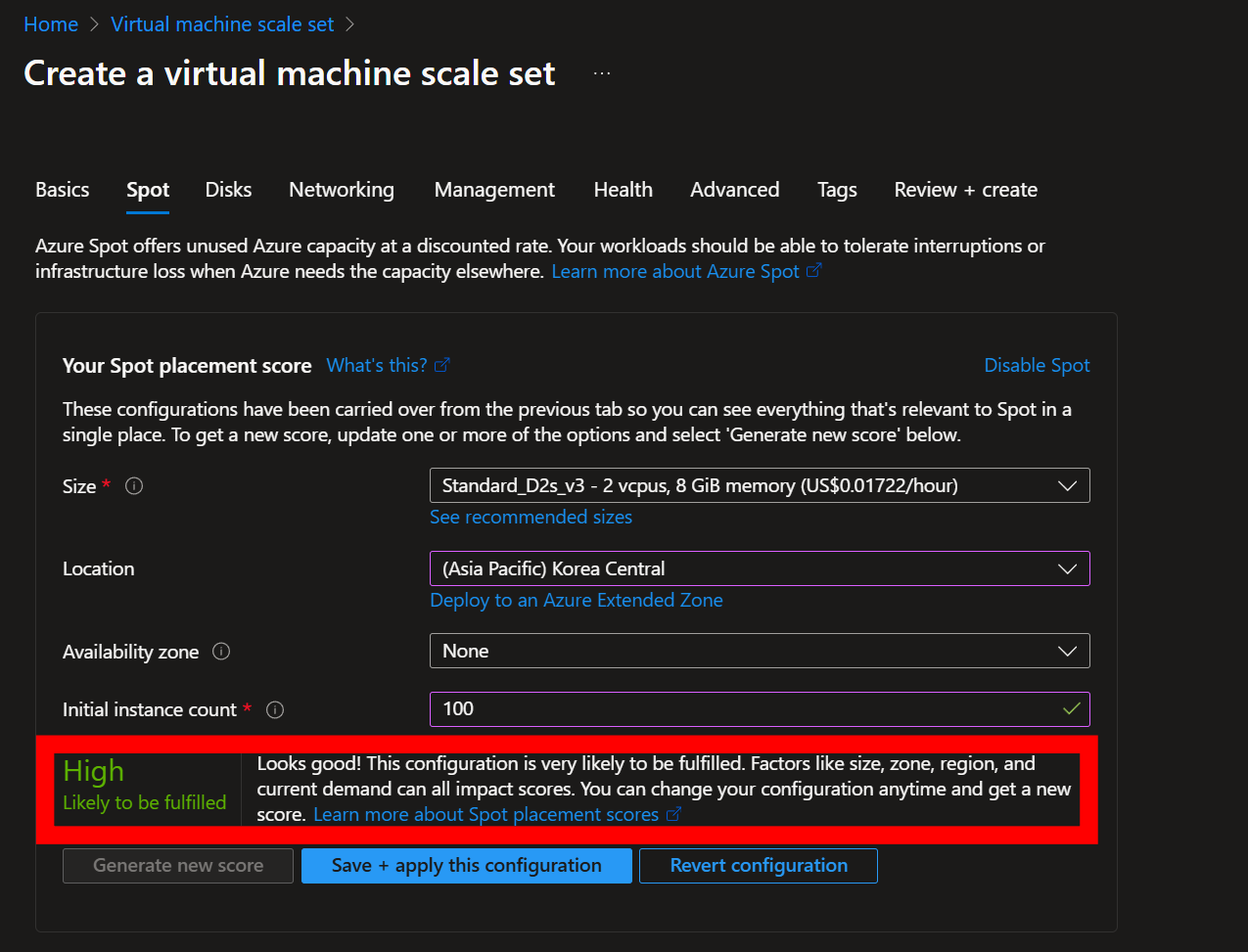 Spot Placement Score는 클라우드 리소스 배포의 성공 가능성을 평가하고 최적화할 수 있는 유용한 도구로, 특히 비용 효율성을 중시하는 사용자들에게 많은 기대를 받고 있습니다. 이 기능은 원하는 Spot VM 수, VM 크기, 배포 지역 및 영역을 고려하여 성공 가능성을 예측하고 이를 "높음," "보통," "낮음"으로 분류해 배포 전략을 지원합니다. 그러나 이러한 장점에도 불구하고, 이를 과신하거나 단독으로 의존하는 것은 위험할 수 있습니다.
우선, Spot Placement Score의 가장 큰 약점은 실시간 동적 환경에서의 변동성을 완전히 반영하지 못한다는 점입니다. Spot 자원은 수요와 공급의 변동에 따라 크게 달라지며, "높음" 점수가 반드시 성공을 보장하지 않습니다. 이 점수는 요청 시점에만 유효하며, 같은 날이라도 시간에 따라 결과가 크게 달라질 수 있습니다. 따라서 배포 전략은 항상 이러한 동적인 환경을 염두에 두어야 합니다.
또한, Spot Placement Score는 특정 구성에만 유효한 점수입니다. 원하는 VM 수, 크기, 위치 및 영역이 조금만 달라져도 해당 점수는 무의미해질 수 있습니다. VM 확장 집합이나 특정 퇴거율과 같은 추가적인 제약 조건은 이 점수에 반영되지 않으므로, 사용자가 별도로 고려해야 합니다. 또한, 구독에 따른 Spot VM 할당량 한도 역시 도구에서 평가하지 않기 때문에, 이러한 한도를 초과한 경우 배포 성공 여부와 상관없이 요청이 거절될 수 있습니다.
결과적으로 Spot Placement Score는 배포 성공률을 높이는 데 도움이 되는 강력한 지표이지만, 모든 문제를 해결하는 만능 도구는 아닙니다. 사용자는 이를 가이드로 활용하되, 실시간 모니터링 및 추가적인 자원 관리 전략을 병행해야만 클라우드 비용과 안정성을 최적화할 수 있습니다. 이러한 점에서 Spot Placement Score는 어디까지나 하나의 도구일 뿐, 종합적인 클라우드 전략의 일부로 활용되어야 한다는 점을 잊어서는 안 됩니다.
Spot Placement Score는 배포 성공 가능성을 평가하고 최적의 리소스 배치를 돕는 유용한 도구이지만, 몇 가지 중요한 단점이 존재합니다. 이러한 단점을 이해하고 대처하는 것이 효과적인 활용의 핵심입니다.
1.실시간 변동성 반영의 한계
Spot 자원은 본질적으로 수요와 공급의 변동에 민감하며, Spot Placement Score는 이를 완벽히 반영하지 못합니다. "높음" 점수가 나왔다고 하더라도, 실제 배포 시점의 자원 가용성이 예측과 달라질 수 있습니다. 점수는 요청 시점에만 유효하며, 시간이 지나거나 환경이 바뀌면 신뢰도가 크게 떨어질 수 있습니다. 따라서, 동일한 조건이라도 다른 시간대나 상황에서 배포 실패 가능성이 존재합니다.
2.제약 조건에 대한 고려 부족
Spot Placement Score는 특정 매개변수(예: VM 크기, 원하는 VM 수, 배포 지역 및 영역)를 기반으로 계산되지만, 다른 제약 조건은 고려하지 않습니다. 예를 들어, VM 확장 집합이나 특정 퇴거율, 또는 단일 배치 그룹과 같은 요소는 점수 산정에서 제외됩니다. 이는 배포 전략을 복잡하게 만들 수 있으며, 결과적으로 예상치 못한 실패를 초래할 수 있습니다.
3.실제 성공 보장 부족
"높음" 점수가 성공을 보장하지 않는다는 점이 가장 큰 단점 중 하나입니다. 이 점수는 과거와 현재의 트렌드를 기반으로 계산되지만, 클라우드 환경의 동적인 특성 때문에 완벽한 예측은 불가능합니다. 또한, 점수 자체가 단순한 추천으로만 작용하며, 실제로 자원을 확보하거나 배포를 성공시키는 데 필요한 세부적인 조건까지 보장하지 않습니다.
4.장기적인 데이터 부족
Spot Placement Score는 실시간 및 단기적인 데이터에 의존하기 때문에, 배포 전략을 장기적으로 계획하려는 사용자에게는 충분한 신뢰성을 제공하지 못할 수 있습니다. 이는 예측적 분석이 부족한 초기 사용자에게 더 큰 단점으로 다가옵니다.
5.복잡성 증가
Spot Placement Score를 활용하기 위해서는 사용자가 매개변수 입력, 점수 분석, 결과를 바탕으로 한 조정 등 여러 단계를 거쳐야 합니다. 이는 클라우드 관리 경험이 적은 사용자에게 추가적인 학습 곡선과 시간 소모를 요구할 수 있습니다. 따라서, 이 도구를 효과적으로 활용하려면 기본적인 클라우드 컴퓨팅 및 Spot 인스턴스 작동 원리에 대한 깊은 이해가 필요합니다.
결론적으로, Spot Placement Score는 유용한 도구이지만, 그 한계를 명확히 이해하고 보완적인 전략을 수립해야 효과적으로 활용할 수 있습니다. 이 기능을 맹신하기보다는 실시간 모니터링, 자원 관리 도구, 그리고 수동적인 대응 전략을 병행하여 배포 성공률과 비용 효율성을 극대화하는 것이 중요합니다.
결론
Spot Placement Score는 클라우드 배포에서 리소스의 가용성 및 비용 효율성을 최적화하는 데 중요한 도구로 자리 잡을 수 있습니다. 이 기능은 배포 성공 가능성을 예측하고, Spot VM의 안정성을 높이기 위한 최적의 지역과 VM 크기를 식별하는 데 큰 도움이 됩니다. 그러나 이 도구는 한계도 명확합니다. 점수는 과거와 현재의 데이터를 기반으로 계산되기 때문에 동적이고 변동적인 클라우드 환경에서는 예측에 오류가 발생할 수 있습니다. 또한, 점수가 성공을 보장하지 않으며, 추가적인 제약 조건이나 구독 할당량 등의 변수는 고려되지 않습니다.
따라서 Spot Placement Score를 효과적으로 활용하려면 이 도구의 한계를 인식하고, 실시간 모니터링 및 추가적인 전략과 함께 사용해야 합니다. 클라우드 리소스를 최적화하려는 기업이나 개인은 이 점수를 하나의 참고자료로 삼되, 리소스 배치에 있어 보다 다각적인 접근을 통해 배포 성공률을 높이고, 실패 위험을 최소화하는 전략을 세워야 합니다. 이 과정에서 다른 클라우드 관리 도구와의 조화로운 사용이 무엇보다 중요합니다.
https://learn.microsoft.com/en-us/azure/virtual-machine-scale-sets/spot-placement-score?tabs=portal?WT.mc_id=AZ-MVP-5002667]]>
Spot Placement Score는 클라우드 리소스 배포의 성공 가능성을 평가하고 최적화할 수 있는 유용한 도구로, 특히 비용 효율성을 중시하는 사용자들에게 많은 기대를 받고 있습니다. 이 기능은 원하는 Spot VM 수, VM 크기, 배포 지역 및 영역을 고려하여 성공 가능성을 예측하고 이를 "높음," "보통," "낮음"으로 분류해 배포 전략을 지원합니다. 그러나 이러한 장점에도 불구하고, 이를 과신하거나 단독으로 의존하는 것은 위험할 수 있습니다.
우선, Spot Placement Score의 가장 큰 약점은 실시간 동적 환경에서의 변동성을 완전히 반영하지 못한다는 점입니다. Spot 자원은 수요와 공급의 변동에 따라 크게 달라지며, "높음" 점수가 반드시 성공을 보장하지 않습니다. 이 점수는 요청 시점에만 유효하며, 같은 날이라도 시간에 따라 결과가 크게 달라질 수 있습니다. 따라서 배포 전략은 항상 이러한 동적인 환경을 염두에 두어야 합니다.
또한, Spot Placement Score는 특정 구성에만 유효한 점수입니다. 원하는 VM 수, 크기, 위치 및 영역이 조금만 달라져도 해당 점수는 무의미해질 수 있습니다. VM 확장 집합이나 특정 퇴거율과 같은 추가적인 제약 조건은 이 점수에 반영되지 않으므로, 사용자가 별도로 고려해야 합니다. 또한, 구독에 따른 Spot VM 할당량 한도 역시 도구에서 평가하지 않기 때문에, 이러한 한도를 초과한 경우 배포 성공 여부와 상관없이 요청이 거절될 수 있습니다.
결과적으로 Spot Placement Score는 배포 성공률을 높이는 데 도움이 되는 강력한 지표이지만, 모든 문제를 해결하는 만능 도구는 아닙니다. 사용자는 이를 가이드로 활용하되, 실시간 모니터링 및 추가적인 자원 관리 전략을 병행해야만 클라우드 비용과 안정성을 최적화할 수 있습니다. 이러한 점에서 Spot Placement Score는 어디까지나 하나의 도구일 뿐, 종합적인 클라우드 전략의 일부로 활용되어야 한다는 점을 잊어서는 안 됩니다.
Spot Placement Score는 배포 성공 가능성을 평가하고 최적의 리소스 배치를 돕는 유용한 도구이지만, 몇 가지 중요한 단점이 존재합니다. 이러한 단점을 이해하고 대처하는 것이 효과적인 활용의 핵심입니다.
1.실시간 변동성 반영의 한계
Spot 자원은 본질적으로 수요와 공급의 변동에 민감하며, Spot Placement Score는 이를 완벽히 반영하지 못합니다. "높음" 점수가 나왔다고 하더라도, 실제 배포 시점의 자원 가용성이 예측과 달라질 수 있습니다. 점수는 요청 시점에만 유효하며, 시간이 지나거나 환경이 바뀌면 신뢰도가 크게 떨어질 수 있습니다. 따라서, 동일한 조건이라도 다른 시간대나 상황에서 배포 실패 가능성이 존재합니다.
2.제약 조건에 대한 고려 부족
Spot Placement Score는 특정 매개변수(예: VM 크기, 원하는 VM 수, 배포 지역 및 영역)를 기반으로 계산되지만, 다른 제약 조건은 고려하지 않습니다. 예를 들어, VM 확장 집합이나 특정 퇴거율, 또는 단일 배치 그룹과 같은 요소는 점수 산정에서 제외됩니다. 이는 배포 전략을 복잡하게 만들 수 있으며, 결과적으로 예상치 못한 실패를 초래할 수 있습니다.
3.실제 성공 보장 부족
"높음" 점수가 성공을 보장하지 않는다는 점이 가장 큰 단점 중 하나입니다. 이 점수는 과거와 현재의 트렌드를 기반으로 계산되지만, 클라우드 환경의 동적인 특성 때문에 완벽한 예측은 불가능합니다. 또한, 점수 자체가 단순한 추천으로만 작용하며, 실제로 자원을 확보하거나 배포를 성공시키는 데 필요한 세부적인 조건까지 보장하지 않습니다.
4.장기적인 데이터 부족
Spot Placement Score는 실시간 및 단기적인 데이터에 의존하기 때문에, 배포 전략을 장기적으로 계획하려는 사용자에게는 충분한 신뢰성을 제공하지 못할 수 있습니다. 이는 예측적 분석이 부족한 초기 사용자에게 더 큰 단점으로 다가옵니다.
5.복잡성 증가
Spot Placement Score를 활용하기 위해서는 사용자가 매개변수 입력, 점수 분석, 결과를 바탕으로 한 조정 등 여러 단계를 거쳐야 합니다. 이는 클라우드 관리 경험이 적은 사용자에게 추가적인 학습 곡선과 시간 소모를 요구할 수 있습니다. 따라서, 이 도구를 효과적으로 활용하려면 기본적인 클라우드 컴퓨팅 및 Spot 인스턴스 작동 원리에 대한 깊은 이해가 필요합니다.
결론적으로, Spot Placement Score는 유용한 도구이지만, 그 한계를 명확히 이해하고 보완적인 전략을 수립해야 효과적으로 활용할 수 있습니다. 이 기능을 맹신하기보다는 실시간 모니터링, 자원 관리 도구, 그리고 수동적인 대응 전략을 병행하여 배포 성공률과 비용 효율성을 극대화하는 것이 중요합니다.
결론
Spot Placement Score는 클라우드 배포에서 리소스의 가용성 및 비용 효율성을 최적화하는 데 중요한 도구로 자리 잡을 수 있습니다. 이 기능은 배포 성공 가능성을 예측하고, Spot VM의 안정성을 높이기 위한 최적의 지역과 VM 크기를 식별하는 데 큰 도움이 됩니다. 그러나 이 도구는 한계도 명확합니다. 점수는 과거와 현재의 데이터를 기반으로 계산되기 때문에 동적이고 변동적인 클라우드 환경에서는 예측에 오류가 발생할 수 있습니다. 또한, 점수가 성공을 보장하지 않으며, 추가적인 제약 조건이나 구독 할당량 등의 변수는 고려되지 않습니다.
따라서 Spot Placement Score를 효과적으로 활용하려면 이 도구의 한계를 인식하고, 실시간 모니터링 및 추가적인 전략과 함께 사용해야 합니다. 클라우드 리소스를 최적화하려는 기업이나 개인은 이 점수를 하나의 참고자료로 삼되, 리소스 배치에 있어 보다 다각적인 접근을 통해 배포 성공률을 높이고, 실패 위험을 최소화하는 전략을 세워야 합니다. 이 과정에서 다른 클라우드 관리 도구와의 조화로운 사용이 무엇보다 중요합니다.
https://learn.microsoft.com/en-us/azure/virtual-machine-scale-sets/spot-placement-score?tabs=portal?WT.mc_id=AZ-MVP-5002667]]>무료 컨트롤 플레인: 보이지 않는 비용
AKS 기본적으로 컨트롤 플레인 비용을 무료로 제공하며, 이는 초기 사용 시 매력적인 옵션으로 보일 수 있습니다. 하지만 이 무료 옵션에는 중요한 단점이 있습니다. SLA 부재: 무료 컨트롤 플레인은 SLA를 보장하지 않습니다. 엔터프라이즈 환경에서 높은 가용성이 요구될 때, SLA가 없는 컨트롤 플레인은 예기치 않은 다운타임이나 장애 시 복구 시간이 길어질 가능성이 큽니다. 이는 직접적인 금전적 손실뿐 아니라, 고객 신뢰에 큰 영향을 미칩니다. 스케일링 제한: 무료 컨트롤 플레인은 극단적으로 많은 워크로드를 처리하기 위한 최적화가 부족할 수 있습니다. 마이크로서비스 구조에서 수천 개의 서비스와 관련된 요청을 처리할 때, 무료 컨트롤 플레인의 한계로 인해 성능 저하가 발생할 가능성이 높습니다.유료 컨트롤 플레인: 엔터프라이즈의 필연적 선택
EKS의 경우, 유료 컨트롤 플레인을 사용하는 비용이 약 $0.10/시간(약 $73/월)으로 책정되어 있습니다. AKS는 기본적으로 무료이지만, 프리미엄 네트워크 또는 부가 서비스 사용 시 비용이 추가될 수 있습니다. 엔터프라이즈 환경에서는 유료 컨트롤 플레인을 선택하는 것이 사실상 필수적인 선택입니다. SLA 보장: 유료 옵션을 통해 99.9% 이상의 SLA를 보장받을 수 있으며, 이는 운영 안정성을 위해 필수적입니다. 다운타임이 초래하는 기회비용을 고려하면 이 비용은 적은 편입니다. 운영 효율성: 유료 컨트롤 플레인은 확장성과 안정성을 보장하기 위해 최적화되어 있어, 대규모 워크로드 처리 시에도 예측 가능한 성능을 제공합니다.클러스터 비용: 극단적으로 증가하는 리소스 소모
AKS와 EKS 모두 워커 노드 비용은 사용자가 부담합니다. 하지만 클러스터 규모가 커질수록 컨트롤 플레인의 부담이 워커 노드로 전이되며, 이로 인해 전체 비용이 급격히 증가할 수 있습니다. 수천 개의 마이크로서비스: 마이크로서비스 아키텍처는 본질적으로 작은 서비스 단위를 독립적으로 운영하는 구조입니다. 이로 인해 클러스터 내에서 수천 개의 팟(Pod), 서비스, 네임스페이스가 생성되며, 컨트롤 플레인의 부하가 비약적으로 증가합니다. 관리 오버헤드: 쿠버네티스는 컨트롤 플레인이 API 요청을 처리하고, 클러스터 상태를 지속적으로 조정하며, 스케일링 정책을 적용하는 데 리소스를 사용합니다. 마이크로서비스가 증가할수록 이러한 작업이 기하급수적으로 늘어나며, 이는 워커 노드와 네트워크 트래픽 비용의 증가로 이어집니다. 고가용성을 위한 중복성의 필요성 고가용성(High Availability, HA)은 클러스터의 단일 장애 지점(Single Point of Failure, SPOF)을 제거하고, 서비스 중단을 방지하기 위해 필수적입니다. AKS와 EKS는 기본적으로 SLA를 보장하는 유료 컨트롤 플레인 옵션을 제공하지만, 고가용성을 실현하려면 다음과 같은 추가적인 중복 리소스가 필요합니다: 컨트롤 플레인 중복:EKS: 기본적으로 멀티 AZ(가용 영역)에 걸쳐 컨트롤 플레인을 중복 배치하여 99.95%의 SLA를 제공합니다. 이는 유료로 제공되며, 사용자 비용에 포함됩니다.AKS: SLA를 보장하려면 Azure Availability Zones를 사용해 중복 클러스터를 설정해야 하며, 별도 구성 및 리소스 비용이 추가됩니다. 워커 노드 중복:클러스터의 워커 노드가 단일 AZ에 의존하지 않도록 각 AZ에 중복 노드를 배치해야 합니다. 이는 노드 비용뿐만 아니라 데이터 전송 비용, 스케일링 비용도 증가시킵니다. 스토리지 중복: Persistent Volume은 지역적 장애를 고려해 복제본을 설정해야 하며, 이는 Azure Managed Disks 또는 Amazon EBS의 비용을 증가시킵니다. 3.쿠버네티스를 실행하는 구성요소 및 모니터링 및 로그 쿠버네티스 실행 및 모니터링 구성 비용 증가: Prometheus, Loki, Grafana의 필요성과 관리 부담 쿠버네티스를 운영하려면 클러스터 상태를 모니터링하고 문제를 진단하기 위한 강력한 도구가 필요합니다. 대표적으로 Prometheus(모니터링), Loki(로그 수집 및 저장), Grafana(시각화)가 널리 사용됩니다. 이들 도구는 뛰어난 기능을 제공하지만, 이를 운영하고 유지하기 위해 추가적인 비용과 관리 부담이 발생합니다. 특히, EKS(Amazon Elastic Kubernetes Service) 환경에서 트러블슈팅을 위한 로그 저장 및 분석은 엔터프라이즈 운영 비용에 상당한 영향을 미칩니다. 쿠버네티스 실행을 위한 필수 구성요소 쿠버네티스 클러스터는 컨트롤 플레인과 워커 노드만으로는 제대로 운영될 수 없습니다. 정상적인 운영과 문제 해결을 위해 다음과 같은 모니터링 및 로깅 도구를 구성해야 합니다: Prometheus: 쿠버네티스 메트릭 수집 및 알림 설정. Loki: 애플리케이션 및 시스템 로그 수집 및 저장. Grafana: Prometheus와 Loki 데이터를 기반으로 시각화 대시보드 제공. 이러한 도구는 고도화된 운영 환경을 지원하지만, 다음과 같은 추가적인 비용을 유발합니다. Prometheus, Loki, Grafana 도입으로 인한 비용 증가 EKS의 로그 트러블슈팅으로 인한 추가 비용 EKS 환경에서 문제를 해결하려면 다음과 같은 작업이 필수적입니다: 애플리케이션 및 시스템 로그 분석: Loki와 같은 도구를 통해 로그를 저장하고, 문제 발생 시 이를 검색 및 분석합니다. 트러블슈팅 데이터를 장기 보관: 장애 분석 및 감사 용도로 로그를 장기 보관해야 하며, 이는 저장 비용을 증가 시킵니다. 추가 서비스 활용: AWS CloudWatch Logs: 기본 로그 관리 옵션이지만 데이터 수집, 저장, 검색에 비용이 발생합니다. Elasticsearch와 같은 고급 로그 분석 도구를 사용할 경우 라이선스 및 운영 비용이 추가됩니다. ArgoCD를 추가한 쿠버네티스 관리 및 비용 증가 쿠버네티스 환경에서 ArgoCD는 GitOps 기반의 지속적 배포(CD, Continuous Deployment) 도구로, 애플리케이션 배포 및 관리 자동화에 중요한 역할을 합니다. 하지만 ArgoCD를 포함한 고도화된 쿠버네티스 관리 환경은 비용 증가와 운영 복잡성을 더욱 가중시킬 수 있습니다. ArgoCD는 Git과 쿠버네티스를 연결하여 코드 변경을 자동으로 반영하고 배포를 관리하는 데 도움을 주지만, 이를 구성하고 운영하려면 추가적인 리소스와 관리 노력이 필요합니다. 4.인적비용 많은 단점 중에 가장 큰 단점은 인적 비용입니다. 쿠버네티스를 운영하는 데 있어 가장 큰 단점 중 하나는 바로 인적 비용입니다. 신규 데브옵스 엔지니어를 채용할 때, 쿠버네티스 관련 교육에 3-4개월 이상의 시간이 소요되며, 이는 초기 생산성을 크게 떨어뜨립니다. 이 교육을 통해 엔지니어는 쿠버네티스의 기본 개념과 작업 흐름, 리소스 관리 방법 등을 숙지해야 하는데, 이는 매우 복잡한 과정입니다. 그 후에도 유지보수에 소요되는 시간은 상당히 많아지는데, 일반적으로 쿠버네티스 운영에 소요되는 데브옵스 시간의 60% 이상이 유지보수와 관리에 소비됩니다. 쿠버네티스 환경은 매우 동적이고, 각종 장애나 인시던트가 빈번히 발생하며, 이를 해결하기 위한 문제 해결 시간이 계속해서 증가합니다. 또한, 기본적인 배포 작업을 위해서도 100개 이상의 YAML 파일과 헬름 차트를 관리해야 하며, 이는 엔지니어에게 큰 관리 부담을 주게 됩니다. 결국, 쿠버네티스를 운영하는 데 드는 인적 비용은 상상보다 훨씬 크고, 이로 인해 대기 중인 인시던트나 문제 해결 속도가 느려지는 악순환이 반복될 수 있습니다. 따라서, 이러한 인적 비용을 최소화하려면 자동화 도구의 도입과 교육을 통한 엔지니어 역량 강화를 지속적으로 진행해야 하며, 이를 관리하는 데 드는 시간과 자원을 적극적으로 최적화해야 합니다. AKS 와 EKS의 경우 Managed 서비스이므로 많은 시간을 줄여주는 역할을 합니다. 그러나 원천적으로 쿠버네티스에 대한 이해를 위해 우리는 너무 많은 시간을 소요해야 합니다 5.복잡성 쿠버네티스를 운영하면서 가장 큰 문제 중 하나는 시스템의 복잡성입니다. 쿠버네티스는 강력하고 유연한 오케스트레이션 툴이지만, 그만큼 설정과 관리가 복잡합니다. 클러스터를 처음 세팅할 때부터 각종 네트워크, 보안, 리소스 관리 등 모든 부분에서 다양한 옵션과 선택지가 존재하며, 이를 제대로 구성하는 데 많은 시간과 전문성이 요구됩니다. 또한, 마이크로서비스 아키텍처를 채택한 환경에서는 각 서비스마다 별도의 설정과 관리가 필요하여, 수백 개의 YAML 파일과 헬름 차트를 다뤄야 하는 상황이 발생합니다. 이러한 복잡한 설정은 배포와 관리의 효율성을 떨어뜨리며, 시스템의 확장성과 유지보수가 더욱 어려워집니다. 쿠버네티스의 높은 학습 곡선 또한 시스템 복잡성을 더욱 심화시키며, 신규 엔지니어나 운영자가 효율적으로 작업을 진행하기 위해서는 지속적인 학습과 경험이 필요합니다. 그뿐만 아니라, 애플리케이션의 상태 모니터링, 로그 관리, 트러블슈팅 과정에서도 복잡한 도구들을 구성하고 통합해야 하므로, 운영팀의 부담이 커지고, 결국 시스템의 관리 비용과 오류 가능성은 더욱 증가하게 됩니다. 6.업데이트 쿠버네티스의 빠른 업데이트 주기는 엔터프라이즈 환경에서는 큰 부담으로 작용할 수 있습니다. 예를 들어, Ubuntu 22.04 LTS와 같은 장기 지원 버전은 수년간 안정적으로 서비스를 운영할 수 있지만, AKS나 EKS와 같은 관리형 쿠버네티스 서비스는 지속적인 버전 업데이트와 패치 적용을 요구합니다. 이 과정에서 매번 새로운 기능이나 버그 수정이 추가되지만, 엔터프라이즈 환경에서는 이러한 빈번한 업데이트가 시스템의 안정성을 위협할 수 있습니다. 특히, 업데이트가 진행될 때마다 기존 설정의 호환성 문제나 의도치 않은 장애가 발생할 수 있으며, 이를 해결하기 위한 트러블슈팅과 테스트 과정은 많은 인적 리소스와 시간을 소모하게 만듭니다. 결과적으로, 쿠버네티스를 안정적으로 운영하기 위해서는 주기적인 모니터링과 대응이 필요하며, 이는 인프라 팀에 상당한 부담을 주고 관리 비용을 급증시킵니다. 엔터프라이즈 환경에서 안정성을 최우선으로 고려할 때, 쿠버네티스의 빠른 업데이트 주기는 효율적인 리소스 운영을 방해하는 주요 요인이 됩니다. 결론 결론적으로, 쿠버네티스는 모든 엔터프라이즈 환경에 적합한 솔루션이 아닙니다. 수천 개의 마이크로서비스를 운영하거나 대규모 트래픽을 처리해야 하는 경우, 멀티 클라우드 요구사항을 충족해야 할 때, 또는 고급 배포 패턴을 활용해야 하는 환경에서는 쿠버네티스가 매우 유용할 수 있습니다. 그러나 서비스의 수가 100개 이하이고, 규모를 예측할 수 있는 IoT 시나리오나 주로 관리형 서비스를 사용하는 경우, 작은 팀 규모와 중소기업 환경에서는 쿠버네티스의 복잡성과 관리 비용을 감당하기 어려운 경우가 많습니다. 이런 경우, 관리형 서비스와 다른 간단한 솔루션들이 더 적합할 수 있습니다. 그럼에도 불구하고, 백엔드 서비스의 자유도와 확장성을 제공하기 위해, 쿠버네티스를 일정 부분 유지하는 것은 팀원들의 커리어 발전과 스킬 향상을 위해 필요할 수 있습니다. 하지만 회사 입장에서는 크게 필요하지 않으며, 비용과 관리 효율성 측면에서 대체 가능한 다른 솔루션이 더 적합할 수 있습니다. 그러므로 필요한 부분에서 아키텍처적으로 조화롭게 사용하는 것이 필요합니다.]]>결론: SOC 2 준수의 핵심은 프로세스와 증거
SOC 2 규정을 준수하는 네트워크 아키텍처를 설계하는 것은 기본입니다. 하지만, 더 중요한 것은 이 설계가 요청-승인-기록이라는 구조화된 프로세스를 통해 일관성 있게 운영되고 있음을 증명하는 것입니다. 이러한 접근 방식은 단순히 인증 요구를 충족하는 것을 넘어, 실제 운영 환경에서도 신뢰할 수 있는 보안을 제공합니다. SOC 2는 "무엇을 했는가?"보다 "어떻게 입증할 것인가?"를 요구합니다. 따라서 조직은 정기 검토와 프로세스를 지속적으로 개선하며, 투명성을 보장하는 증거 관리에 초점을 맞춰야 합니다. Azure의 도구와 정책을 효과적으로 활용하여 이를 달성한다면, 규정 준수를 넘어 안전하고 신뢰할 수 있는 서비스 제공자로 자리 잡을 수 있습니다. ISMS-P와 SOC 2는 보안과 인증 체계에서 각기 다른 초점과 접근 방식을 가지고 있습니다. ISMS-P는 한국의 법적 기준에 기반하여 정보 보호와 개인정보 관리에 대한 기술적 보호 조치를 매우 상세히 요구하는 반면, SOC 2는 프로세스와 절차의 일관된 운영과 투명성을 강조하는 특성을 가지고 있습니다. ISMS-P는 기술적 보호 조치 측면에서 세밀한 기준을 요구하며, 접근 통제, 로그 관리, 데이터 암호화, 취약점 관리 등 매우 구체적이고 엄격한 요구 사항을 충족해야 합니다. 인증을 준비하는 과정에서 이러한 기술적 요구 사항을 충족하는 것이 가장 중요한 과제로, 이를 충족하면 비교적 예측 가능하고 일정한 결과를 얻을 수 있습니다.